一種多模態引導的高保真度圖像壓縮方法、系統及介質
本發明涉及圖像處理,特別涉及一種多模態引導的高保真度圖像壓縮方法、系統及介質。
背景技術:
1、圖像壓縮對于高效的數據存儲和傳輸是十分重要的。傳統的圖像壓縮方法,如jpeg、jpeg2000和bpg等技術因其成熟的標準化流程在各種應用中被廣泛使用。近年來隨著深度學習的發展,許多基于深度學習的神經網絡圖像壓縮方法達到了比這些傳統圖像壓縮方法更好的性能。但是隨著多模態業務的發展,對圖像、文字、音頻等多媒體數據同步傳輸成為一種普遍情況。而多模態業務中,同一時間傳輸的多模態信號通常是對同一事物的不同方面的表述,所以它們存在內生的語義關聯。為了發揮多模態數據的優勢,部分圖像壓縮領域的研究人員探索了利用多模態引導的圖像壓縮,并有效提升了壓縮圖像的感知質量。
2、目前的多模態圖像壓縮方法存儲以下缺陷:
3、一、目前的多模態引導圖像壓縮方法大多只使用了文本和圖像模態,而對于多媒體任務,音頻經常是與圖像同時傳輸的模態,為多媒體任務提供更全面的理解。例如,在遠程醫療中,醫生通過音頻解說圖像內容,音頻可以幫助壓縮算法優先保留關鍵的醫學細節。探索音頻是否對圖像壓縮有引導作用是十分必要且未曾嘗試過的領域。
4、二、在文本引導的圖像壓縮方法中,多模態特征融合模塊只在空間維度上進行局部的文本特征對圖像特征的引導,忽略了文本特征在通道維度上對圖像特征的全局引導作用,因此,多模態特征融合模塊還存在大量的優化空間。
5、三、現有文本引導的圖像壓縮方法在引入其他模態信息時,由于特征融合模塊的特征提取與表達能力不足,通常會導致重建圖像的像素保真度(psnr)下降。
技術實現思路
1、本發明的主要目的在于提出一種多模態引導的高保真度圖像壓縮方法、系統及介質,旨在增強圖像特征的提取和表達能力,更好地預測潛在特征的分布,獲得高保真度的圖像。
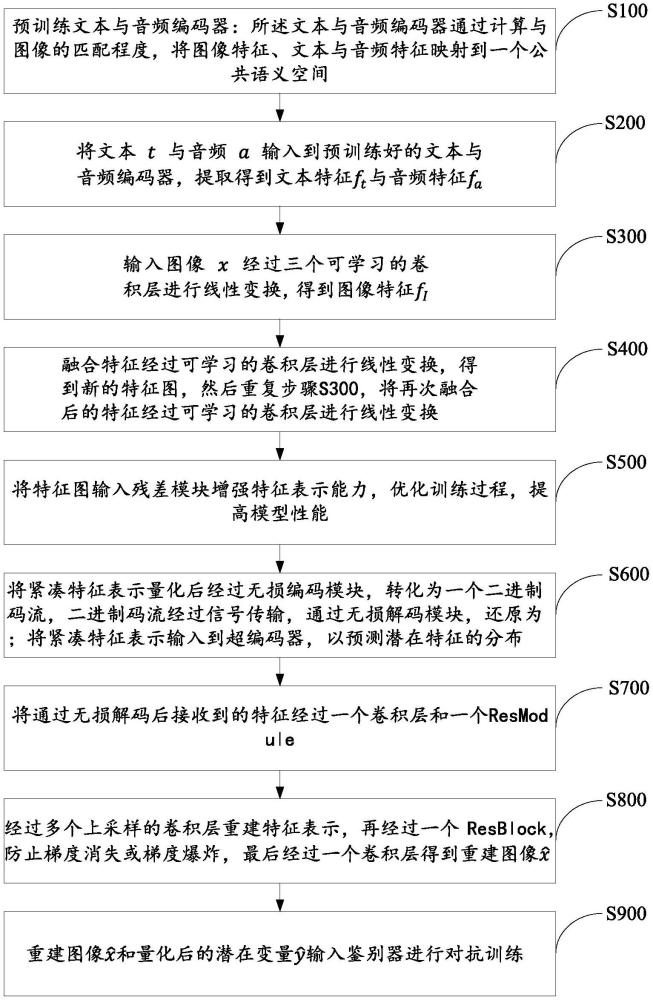
2、為實現上述目的,本發明提供了一種多模態引導的高保真度圖像壓縮方法,包括以下步驟:
3、步驟s100,預訓練文本與音頻編碼器:所述文本與音頻編碼器通過計算與圖像的匹配程度,將圖像特征、文本與音頻特征映射到一個公共語義空間;
4、步驟s200,將文本t與音頻a輸入到預訓練好的文本與音頻編碼器,提取得到文本特征ft與音頻特征fa;
5、步驟s300,輸入圖像x經過三個可學習的卷積層進行線性變換,得到圖像特征fi;
6、步驟s400,融合特征經過可學習的卷積層進行線性變換,得到新的特征圖,然后重復步驟s300,將再次融合后的特征經過可學習的卷積層進行線性變換;
7、步驟s500,將特征圖輸入殘差模塊增強特征表示能力,優化訓練過程,提高模型性能;
8、步驟s600,將緊湊特征表示y量化后經過無損編碼模塊,轉化為一個二進制碼流,二進制碼流經過信號傳輸,通過無損解碼模塊,還原為將緊湊特征表示y輸入到超編碼器,以預測潛在特征的分布;
9、步驟s700,將通過無損解碼后接收到的特征經過一個卷積層和一個resmodule;
10、步驟s800,經過多個上采樣的卷積層重建特征表示,再經過一個resblock,防止梯度消失或梯度爆炸,最后經過一個卷積層得到重建圖像
11、步驟s900,重建圖像和量化后的潛在變量輸入鑒別器進行對抗訓練。
12、本發明進一步的技術方案是,所述步驟s100包括:
13、步驟s110,將輸入文本t與音頻a表示為低維嵌入特征,其中文本編碼器使用雙向長短期記憶循環神經網絡,音頻編碼器使用卷積神經網絡和循環神經網絡;
14、步驟s120:使用預訓練好的圖像編碼器將輸入圖像x表示為低維嵌入特征,圖像編碼器使用卷積神經網絡,將圖像映射到語義向量;
15、步驟s130:通過深度注意力多模態相似度模型訓練步驟s110和步驟s120中的文本編碼器與圖像編碼器,其中,訓練過程中使用注意力驅動的圖像-文本匹配分數,通過基于圖像和文本之間的注意力模型來衡量圖像-句子對的匹配度,使得訓練得到的文本與圖像編碼器能夠有效地將文本與圖像特征映射到公共語義空間;
16、步驟s140:通過同樣的步驟訓練音頻編碼器,使得音頻與圖像編碼器能夠有效地將音頻與圖像特征映射到公共語義空間。
17、本發明進一步的技術方案是,所述步驟s300包括:
18、步驟s310,設計特征融合模塊,其中,所述特征融合模塊只是融合圖像與文本或音頻兩種模態;所述設計特征融合模塊采用的計算公式為:
19、f′t/a=conv3×3(ft/a)
20、γ=σ(conv3×3(f′t/a))
21、β=conv1×1(g(f′t/a))
22、f′image=γ·fimage+β
23、其中,ft/a表示文本特征或語音特征,f′t/a表示經過3×3卷積操作的文本特征或語音特征,σ表示sigmoid激活函數,g表示平均池化操作,y與β分別表示縮放因子與偏移因子,fimage與f′image分別表示處理前后的圖像特征
24、步驟s320,設計多模態特征融合模塊,所述多模態特征融合模塊能在融合兩種模態特征的同時,滿足融合三種模態的需求;所述設計多模態特征融合模塊采用的公式為:
25、fit=fusion(fimage,ftext)
26、fia=fusion(fimage,faudio)
27、fita=con1×1(concat(fit,fia))
28、其中,fusion表示使用特征融合模塊進行特征融合操作,fimage、ftext和faudio分別表示圖像、文本和語音特征,fit、fia和fita分別表示圖文、圖音和圖文音融合特征,concat表示通道維度的拼接操作。
29、本發明進一步的技術方案是,所述步驟s310包括:
30、步驟s311,將文本特征或語音特征ft/a輸入到一個3×3的卷積層,以將其轉換到圖像特征的公共語義空間;
31、步驟s312:對上一步生成的特征圖進行3×3卷積操作以計算每個位置的縮放因子y,這一步生成的特征圖的每個位置表示一個縮放因子y,控制著圖像特征的具體調整,然后將卷積后的輸出通過sigmoid激活函數,生成在[0,1]的范圍內的縮放因子,用于控制圖像特征的縮放程度,每個特征圖的元素可以根據其對應的y值進行放大或縮小,進而調整特征圖的細節;
32、步驟s313:先通過average?pool操作在特征圖的通道維度上進行全局平均池化,計算每個通道的平均值,這一步將每個通道的空間信息匯聚到一個單一的值,從而生成通道級別的統計信息,對池化后的結果應用1×1卷積,以生成每個通道的偏移因子β;
33、步驟s314:通過縮放因子y和偏移因子β操縱輸入圖像特征fimage。
34、本發明進一步的技術方案是,所述步驟s320包括:
35、步驟s321,將圖像特征和文本特征輸入同一個特征融合模塊,而圖像特征和音頻特征輸入另一個特征融合模塊,兩個模塊輸出各自的融合特征;
36、步驟s322:將兩個輸出融合特征在通道上進行concat操作拼接成一個更大的特征,為后續處理提供包含三種模態特征的豐富信息;
37、步驟s323:在拼接特征之后,經過一個1×1卷積以調整通道數,使得最終的特征圖具有合適的維度。
38、本發明進一步的技術方案是,所述步驟s600包括:
39、步驟s610,特征表示y經過兩個卷積層后與文本與音頻特征一起輸入到多模態特征融合模塊,由于潛在特征的分布與圖像的內容密切相關,且文本與音頻描述可以提供圖像的語義信息,所以通過多模態特征融合模塊幫助預測潛在特征的分布,之后,再經過一個卷積層得到z;
40、步驟s620:將z量化后經過無損編碼模塊,轉化為一個二進制碼流傳輸,之后通過無損解碼模塊,還原為經過由三個卷積模塊組成的超解碼器后得到潛在特征的分布,并將其輸送到對應無損編解碼模塊。
41、為實現上述目的,本發明還提出一種多模態引導的高保真度圖像壓縮系統,其特征在于,所述系統包括存儲器、處理器以及存儲在所述處理器上的多模態引導的高保真度圖像壓縮程序,所述多模態引導的高保真度圖像壓縮程序被所述處理器運行時執行如上所述的方法的步驟。
42、為實現上述目的,本發明還提出一種計算機可讀存儲介質,所述計算機可讀存儲介質存儲有多模態引導的高保真度圖像壓縮程序,所述多模態引導的高保真度圖像壓縮程序被所述處理器運行時執行如上所述的方法的步驟。
43、本發明多模態引導的高保真度圖像壓縮方法、系統及介質的有益效果是:
44、本發明利用與圖像語義相關的模態(文本、音頻)引導實現高保真度的圖像壓縮,首次探索音頻在圖像壓縮過程中的引導作用。此外,設計的特征融合模塊不僅可以在空間維度上進行局部細粒度的圖像特征引導,還可以在通道維度上對圖像特征進行全局引導。同時,該模塊具有多尺度結構的優越性,在有著良好的特征融合能力的同時,還可以增強網絡的非線性表達能力。
- 還沒有人留言評論。精彩留言會獲得點贊!