一種基于transformer模型的GPU推理性能優(yōu)化方法、系統(tǒng)、設(shè)備及存儲(chǔ)介質(zhì)與流程
本發(fā)明屬于人工智能,涉及到深度學(xué)習(xí)gpu推理優(yōu)化技術(shù),具體涉及到一種基于transformer模型的gpu推理性能優(yōu)化方法、系統(tǒng)、設(shè)備及存儲(chǔ)介質(zhì)。
背景技術(shù):
1、隨著深度學(xué)習(xí)技術(shù)的不斷進(jìn)步,transformer模型憑借其卓越的性能在自然語(yǔ)言處理(nlp)和計(jì)算機(jī)視覺(jué)(cv)領(lǐng)域獲得了廣泛關(guān)注。transformer模型的核心是自注意力機(jī)制,能夠高效捕捉序列數(shù)據(jù)中的上下文信息。然而,transformer在gpu上的推理性能一直是其應(yīng)用的一個(gè)瓶頸,特別是在智能駕駛等算力資源受限的領(lǐng)域。在這些場(chǎng)景中,推理速度的快慢直接關(guān)系到系統(tǒng)的響應(yīng)時(shí)間和用戶體驗(yàn)。因此,提升transformer在gpu上的推理性能顯得尤為重要。通過(guò)優(yōu)化gpu上的推理過(guò)程,可以加快模型的響應(yīng)速度,降低延遲,從而滿足實(shí)時(shí)應(yīng)用的需求,進(jìn)一步拓寬transformer模型的應(yīng)用范圍。
技術(shù)實(shí)現(xiàn)思路
1、針對(duì)上述問(wèn)題,本發(fā)明的主要目的在于設(shè)計(jì)一種基于transformer模型的gpu推理性能優(yōu)化方法、系統(tǒng)、設(shè)備及存儲(chǔ)介質(zhì),采用迭代搜索、模式匹配、算子替換和融合的方式,提升transformer在gpu上的推理性能。
2、為了實(shí)現(xiàn)上述目的本發(fā)明采用如下技術(shù)方案:
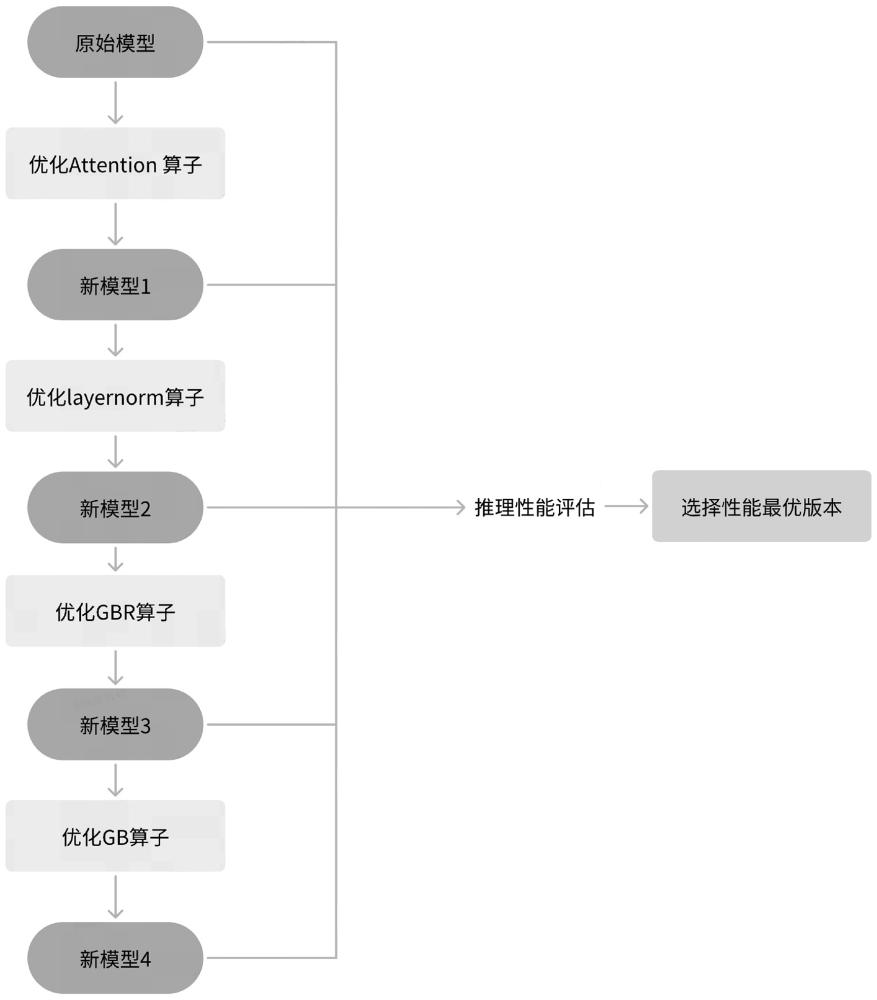
3、一種基于transformer模型的gpu推理性能優(yōu)化方法,該方法運(yùn)行在nvidia芯片平臺(tái),使用python腳本結(jié)合tensorrt和cuda工具進(jìn)行推理性能優(yōu)化,具體包括如下步驟:
4、獲取原始o(jì)nnx模型model_0;使用輸入數(shù)據(jù)通過(guò)onnx模型運(yùn)行推理,并記錄初始性能指標(biāo),記為p_0;
5、優(yōu)化原始o(jì)nnx模型model_0中的attention算子,得到新模型model_1;對(duì)model_1進(jìn)行推理性能評(píng)估,記為p_1;
6、優(yōu)化模型model_1中的layernorm算子,得到新模型model_2;對(duì)model_2進(jìn)行推理性能評(píng)估,記為p_2;
7、優(yōu)化模型model_2中的gbr算子,得到新模型model_3;對(duì)model_3進(jìn)行推理性能評(píng)估,記為p_3;
8、優(yōu)化模型model_3中的gb算子,得到新模型model_4;對(duì)model_4進(jìn)行推理性能評(píng)估,記為p_4;
9、將原始模型性能p_0、優(yōu)化attention算子后的性能p_1、優(yōu)化layernorm算子后的性能p_2、優(yōu)化gbr算子后的性能p_3、優(yōu)化gb算子后的性能p_4進(jìn)行比較,找出性能最優(yōu)的模型版本,記為model_best,即為上述方法的最優(yōu)模型和最佳性能優(yōu)化結(jié)果。
10、作為本發(fā)明進(jìn)一步的描述,優(yōu)化原始o(jì)nnx模型model_0中的attention算子,包括如下步驟:
11、迭代搜索原始o(jì)nnx模型model_0的網(wǎng)絡(luò)圖,逐層遍歷模型model_0中的網(wǎng)絡(luò)層,進(jìn)行網(wǎng)絡(luò)層上下文模式匹配;
12、其中,attention算子由2個(gè)matmul層+1個(gè)softmax層構(gòu)成;
13、在模型model_0中查找到所有的attention算子后,將其均替換為自定義融合的attentionfusionop算子,attentionfusionop為模型model_0中attention算子結(jié)構(gòu)進(jìn)行重新融合后得到的自定義算子;
14、換完成后,得到的新onnx模型記為model_1。
15、作為本發(fā)明進(jìn)一步的描述,優(yōu)化模型model_1中的layernorm算子,包括如下步驟:
16、迭代搜索模型model_1的網(wǎng)絡(luò)圖,逐層遍歷模型model_1中的網(wǎng)絡(luò)層,進(jìn)行網(wǎng)絡(luò)層上下文模式匹配;
17、其中,layernorm算子包括2個(gè)add算子,2個(gè)reducemean算子,一個(gè)sub算子,一個(gè)pow算子,一個(gè)sqrt算子,一個(gè)div算子和一個(gè)mul算子;
18、在模型model_1中查找到所有的layernorm算子后,將其替換為自定義融合的lnfusionop算子,lnfusionop為模型model_1中l(wèi)ayernorm算子結(jié)構(gòu)進(jìn)行重新融合后得到的自定義算子;
19、替換完成后,得到的新onnx模型記為model_2。
20、作為本發(fā)明進(jìn)一步的描述,優(yōu)化模型model_2中的gbr算子,包括如下步驟:
21、迭代搜索模型model_2的網(wǎng)絡(luò)圖,逐層遍歷模型model_2中的網(wǎng)絡(luò)層,進(jìn)行網(wǎng)絡(luò)層上下文模式匹配;
22、其中,gbr算子為matmul+add+relu三個(gè)算子的融合;
23、在模型model_2中查找到所有的gbr算子后,將其替換為自定義融合的gbrfusionop算子,gbrfusionop為模型model_2中g(shù)br算子結(jié)構(gòu)gemm+bias+relu進(jìn)行重新融合后得到的自定義算子;
24、替換完成后,得到的新onnx模型記為model_3。
25、作為本發(fā)明進(jìn)一步的描述,優(yōu)化模型model_3中的gb算子,包括如下步驟:
26、迭代搜索模型model_3的網(wǎng)絡(luò)圖,逐層遍歷模型model_3中的網(wǎng)絡(luò)層,進(jìn)行網(wǎng)絡(luò)層上下文模式匹配;
27、其中,gb算子為matmul+add兩個(gè)算子的融合;
28、在模型model_3中查找到所有的gb算子后,將其替換為自定義融合的gbfusionop算子,gbfusionop為模型model_3中g(shù)b算子結(jié)構(gòu)gemm+bias進(jìn)行重新融合后得到的自定義算子;
29、替換完成后,得到的新onnx模型記為model_4。
30、作為本發(fā)明進(jìn)一步的描述,性能p_0、性能p_1、性能p_2、性能p_3的比較,包括如下步驟:
31、分別使用model_0、model_1、model_2、model_3在同一設(shè)備環(huán)境下進(jìn)行模型的推理操作;
32、統(tǒng)計(jì)預(yù)設(shè)次數(shù)推理的總計(jì)耗時(shí),并求平均耗時(shí);
33、根據(jù)平均耗時(shí)評(píng)估各個(gè)算子優(yōu)化情況下的性能優(yōu)劣。
34、一種基于transformer模型的gpu推理性能優(yōu)化系統(tǒng),該系統(tǒng)用于執(zhí)行上述的性能優(yōu)化方法,包括原始模型獲取推理模塊、attention算子優(yōu)化模塊、layernorm算子優(yōu)化模塊、gbr算子優(yōu)化模塊、gb算子優(yōu)化模塊、性能比較模塊;
35、所述原始模型獲取推理模塊,用于獲取onnx模型model_0,并通過(guò)輸入數(shù)據(jù)進(jìn)行推理,得到模型model_0初始性能p_0;
36、所述attention算子優(yōu)化模塊,用于遍歷模型model_0,找到并替換attention算子得到model_1,并通過(guò)輸入數(shù)據(jù)進(jìn)行推理,得到模型model_1的性能p_1;
37、所述layernorm算子優(yōu)化模塊,用于遍歷模型model_1,找到并替換layernorm算子得到model_2,并通過(guò)輸入數(shù)據(jù)進(jìn)行推理,得到model_2的性能p_2;
38、所述gbr算子優(yōu)化模塊,用于遍歷模型model_2,找到并替換gbr算子得到model_3,并通過(guò)輸入數(shù)據(jù)進(jìn)行推理,得到model_3的性能p_3;
39、所述gb算子優(yōu)化模塊,用于遍歷模型model_3,找到并替換gb算子得到model_4,并通過(guò)輸入數(shù)據(jù)進(jìn)行推理,得到model_4的性能p_4;
40、所述性能比較模塊,通過(guò)上述性能p_1、性能p_2、性能p_3、性能p_4進(jìn)行比較,找出性能最優(yōu)的模型版本,得到最優(yōu)模型和最佳性能優(yōu)化結(jié)果。
41、一種電子設(shè)備,包括處理器、通信接口、存儲(chǔ)器和通信總線,其中,所述處理器、所述通信接口和所述存儲(chǔ)器通過(guò)所述通信總線完成相互間的通信,所述存儲(chǔ)器,用于存儲(chǔ)計(jì)算機(jī)程序;
42、所述處理器,用于通過(guò)運(yùn)行所述存儲(chǔ)器上所存儲(chǔ)的所述計(jì)算機(jī)程序來(lái)執(zhí)行上述的性能優(yōu)化方法。
43、一種計(jì)算機(jī)可讀的存儲(chǔ)介質(zhì),所述存儲(chǔ)介質(zhì)中存儲(chǔ)有計(jì)算機(jī)程序,其中,所述計(jì)算機(jī)程序被處理器執(zhí)行時(shí)實(shí)現(xiàn)上述的性能優(yōu)化方法。
44、相對(duì)于現(xiàn)有技術(shù),本發(fā)明的技術(shù)效果為:
45、本發(fā)明提供了一種基于transformer模型的gpu推理性能優(yōu)化方法、系統(tǒng)、設(shè)備及存儲(chǔ)介質(zhì),該性能優(yōu)化方法為通用的transformer模型推理性能調(diào)優(yōu)策略,適用于多種應(yīng)用場(chǎng)景和模型類(lèi)型,通過(guò)自定義算子替換和融合,實(shí)現(xiàn)對(duì)attention算子、layernorm算子、gbr算子、gb算子等的優(yōu)化,顯著減少計(jì)算量或內(nèi)存的使用,提升模型性能,具體的優(yōu)化步驟包括迭代搜索、模式匹配、算子替換和融合,提升深度學(xué)習(xí)模型的訓(xùn)練速度和推理速度,且降低資源消耗和成本。
- 還沒(méi)有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!