基于深度學習的知識產權侵權檢測算法的制作方法
本發明涉及知識產權保護,更具體地說,涉及基于深度學習的知識產權侵權檢測算法。
背景技術:
1、知識產權侵權是指未經知識產權所有者許可,擅自使用、復制、傳播、修改或銷售受知識產權保護的作品、發明、商標等行為,侵犯了知識產權所有者的合法權益。
2、傳統的知識產權侵權檢測往往依賴大量人工進行比對和判斷,這不僅耗時費力,而且容易受到主觀因素影響,知識產權侵權手段不斷翻新和變化,傳統的檢測方法往往難以適應新的侵權形式,深度學習算法通過學習大量的樣本數據,能夠總結出一般性的特征和規律,具有較強的泛化能力。
技術實現思路
1、針對現有技術中存在的問題,本發明的目的在于提供基于深度學習的知識產權侵權檢測算法。
2、為解決上述問題,本發明采用如下的技術方案;
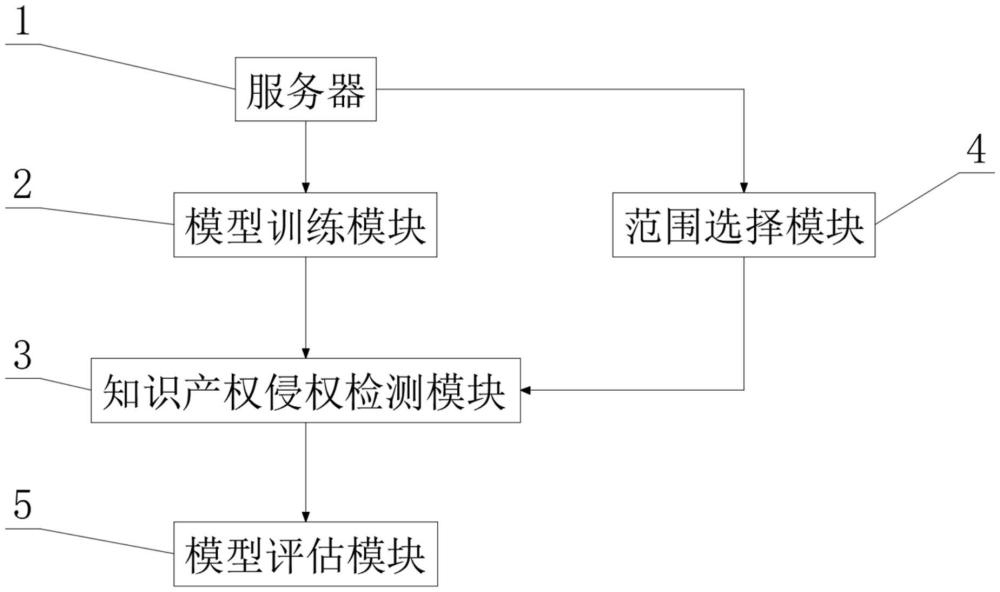
3、基于深度學習的知識產權侵權檢測算法,包括:服務器、模型訓練模塊、知識產權侵權檢測模型、范圍選擇模塊與模型評估模塊;
4、所述服務器用于存儲現有知識產權數據,并對存儲的知識產權數據實時更新;
5、所述模型訓練模塊用于收集服務器的現有知識產權數據進行預處理,并將處理后的知識產權數據作為訓練集對知識產權侵權檢測模型進行訓練;
6、所述知識產權侵權檢測模型用于輸入所需檢測待檢測知識產權數據,模型輸出侵權的概率或判斷結果,根據設定的閾值來確定是否存在侵權;
7、所述范圍選擇模塊用于根據待檢測知識產權數據的時間,來選擇服務器中的現有知識產權數據的范圍,并將選擇后的現有知識產權數據輸入所述知識產權侵權檢測模型中;
8、所述模型評估模塊用于對訓練后的知識產權侵權檢測模型進行分析評估,未合格知識產權侵權檢測模型則繼續通過模型訓練模塊訓練。
9、作為上述技術方案的進一步描述:
10、所述服務器包含有數據庫與更新模塊,所述數據庫用于存儲現有知識產權數據,所述更新模塊用于更新數據庫中的知識產權數據。
11、作為上述技術方案的進一步描述:
12、所述模型訓練模塊的訓練步驟如下:
13、數據預處理,通過對收集的現有知識產權數據進行預處理,預處理包括數據清洗、歸一化與特征標注,然后作為訓練知識產權侵權檢測模型的訓練集;
14、特征提取,將處理后的訓練集輸入到知識產權侵權檢測模型中對數據進行特征提取,學習數據的內在特征,提取特征包括知識產權的新穎性、創造性與實用性;
15、模型訓練,將提取的特征輸入到知識產權侵權檢測模型中進行訓練,調整模型的參數以最小化損失函數。
16、作為上述技術方案的進一步描述:
17、所述知識產權侵權檢測模型包含有循環神經網絡與長短期記憶網絡。
18、作為上述技術方案的進一步描述:
19、所述范圍選擇模塊的時間選擇依據待檢測知識產權的申請日、公開日與授權日,其中新穎性與創造性對比選擇申請日前或申請日后的現有知識產權進行侵權檢測。
20、作為上述技術方案的進一步描述:
21、所述模型評估模塊的評估方式為判斷待檢測知識產權數據與現有知識產權數據的相關相似度的闕值,其中相關相似度包括知識產權有益效果相識度、結構相似度與內容相似度。
22、作為上述技術方案的進一步描述:
23、所述長短期記憶網絡存儲與更新算法如下:
24、遺忘門,接收當前輸入xt和上一個時間步的隱藏狀態ht-1,通過一個全連接層和一個sigmoid激活函數來計算遺忘門的輸出ft,取值范圍在0到1之間,ft的值越接近1,表示保留的信息越多;越接近0,表示遺忘的信息越多:
25、ft=σ(wf×[ht-1,xt]+bf);
26、其中為wf遺忘門權重,bf為偏置項,σ為sigmoid激活函數;
27、輸入門,同樣接收當前輸入xt和上一個時間步的隱藏狀態ht-1,通過兩個全連接層和一個sigmoid激活函數以及一個tanh激活函數來計算輸入門的輸出it和新的候選記憶單元狀態c~t,計算公式如下:
28、it=σ(wi×[ht-1,xt]+bi);
29、c~t=tanh(wc×[ht-1,xt]+bc);
30、其中wi與wc分別為輸入門與候選記憶單元狀態的權重矩陣,bi與bc為偏置項;
31、根據遺忘門與輸入門的輸出,更新記憶單元的狀態ct,計算公式如下:
32、ct=ft⊙ct-1+it⊙c~t
33、輸出門,它接收當前輸入xt和上一個時間步的隱藏狀態ht-1,通過一個全連接層和一個sigmoid激活函數來計算輸出門的輸出ot,然后將ot與經過tanh激活函數處理的記憶單元狀態ct相乘,得到當前時間步的隱藏狀態ht。計算公式如下:
34、ot=σ(wo×[ht-1,xt]+bo);
35、ht=ot⊙tanh(ct);
36、其中wo為輸出門的權重矩陣,bo為偏置項。
37、相比于現有技術,本發明的優點在于:
38、本方案,基于深度學習的算法能夠自動提取特征、進行模式識別和比對分析,極大地減少了人工干預的需求,無需人工逐一查看,且能夠根據侵權手段更新進一步學習來檢測侵權行為;對知識產權數據在檢測前進行劃分,能夠降低檢測模型的算力壓力,提高檢測模型的檢測效率與精確性。
技術特征:
1.基于深度學習的知識產權侵權檢測算法,其特征在于,包括:服務器(1)、模型訓練模塊(2)、知識產權侵權檢測模型(3)、范圍選擇模塊(4)與模型評估模塊(5);
2.根據權利要求1所述的基于深度學習的知識產權侵權檢測算法,其特征在于:所述服務器(1)包含有數據庫(11)與更新模塊(12),所述數據庫(11)用于存儲現有知識產權數據,所述更新模塊(12)用于更新數據庫(11)中的知識產權數據。
3.根據權利要求1所述的基于深度學習的知識產權侵權檢測算法,其特征在于:所述模型訓練模塊(2)的訓練步驟如下:
4.根據權利要求1所述的基于深度學習的知識產權侵權檢測算法,其特征在于:所述知識產權侵權檢測模型(3)包含有循環神經網絡(31)與長短期記憶網絡(32)。
5.根據權利要求1所述的基于深度學習的知識產權侵權檢測算法,其特征在于:所述范圍選擇模塊(4)的時間選擇依據待檢測知識產權的申請日、公開日與授權日,其中新穎性與創造性對比選擇申請日前或申請日后的現有知識產權進行侵權檢測。
6.根據權利要求1所述的基于深度學習的知識產權侵權檢測算法,其特征在于:所述模型評估模塊(5)的評估方式為判斷待檢測知識產權數據與現有知識產權數據的相關相似度的闕值,其中相關相似度包括知識產權有益效果相識度、結構相似度與內容相似度。
7.根據權利要求4所述的基于深度學習的知識產權侵權檢測算法,其特征在于:所述長短期記憶網絡(32)存儲與更新算法如下:
技術總結
本發明公開了基于深度學習的知識產權侵權檢測算法,包括:服務器、模型訓練模塊、知識產權侵權檢測模型、范圍選擇模塊與模型評估模塊;所述服務器用于存儲現有知識產權數據,并對存儲的知識產權數據實時更新;所述模型訓練模塊用于收集服務器的現有知識產權數據進行預處理,并將處理后的知識產權數據作為訓練集對知識產權侵權檢測模型進行訓練。本發明,無需人工逐一查看,且能夠根據侵權手段更新進一步學習來檢測侵權行為;對知識產權數據在檢測前進行劃分,能夠降低檢測模型的算力壓力,提高檢測模型的檢測效率與精確性。
技術研發人員:葛海桃,張宗愛
受保護的技術使用者:行有恒科技(江蘇)有限公司
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!