基于語義的圖像聚類方法及裝置、存儲介質、電子裝置與流程
本發明涉及人工智能,具體而言,涉及一種基于語義的圖像聚類方法及裝置、存儲介質、電子裝置。
背景技術:
1、相關技術中,圖像聚類是機器學習領域中最基本的無監督學習任務,其核心思想是基于相似性度量將相似的數據劃分到同一類,不相似的數據分到不同類。近年來,隨著大數據與人工智能的發展,人們對大量無標簽數據進行分析與處理的需求日益加大,對聚類也越來越重視。在過去幾十年,發展出了如k-均值聚類(k-means),譜聚類(spectra?l?c?luster?i?ng,sc),高斯混合聚類(gauss?i?an?mi?xed?mode?l,gmm)和非負矩陣分解聚類(non-negat?i?ve?matr?i?x?factor?i?zat?i?on,nmf)等經典方法,有效地解決了較低維度的數據聚類問題。
2、相關技術中,傳統的聚類方法都依賴于手工提取的特征。然而,對于高維大規模復雜數據,傳統的聚類方法面臨如下問題:首先,高維空間中,數據點之間的距離將趨向于相等,導致基于距離的聚類方法失效;其次,高維數據導致計算復雜度急劇上升;最后,高維數據往往會出現冗余特征且有噪聲,嚴重影響聚類性能。目前解決高維數據聚類的方法主要是:對高維數據進行降維或者特征變換,將原始高維數據映射到低維特征空間中,然后對得到的低維特征采用傳統方法進行聚類。相關技術在進行聚類時,由于無法準確提取到圖像的語義特征,導致在降維映射時關鍵特征丟失,進而導致聚類不準確。
3、針對相關技術中存在的上述問題,暫未發現高效且準確的解決方案。
技術實現思路
1、本發明提供了一種基于語義的圖像聚類方法及裝置、存儲介質、電子裝置,以解決相關技術中的技術問題。
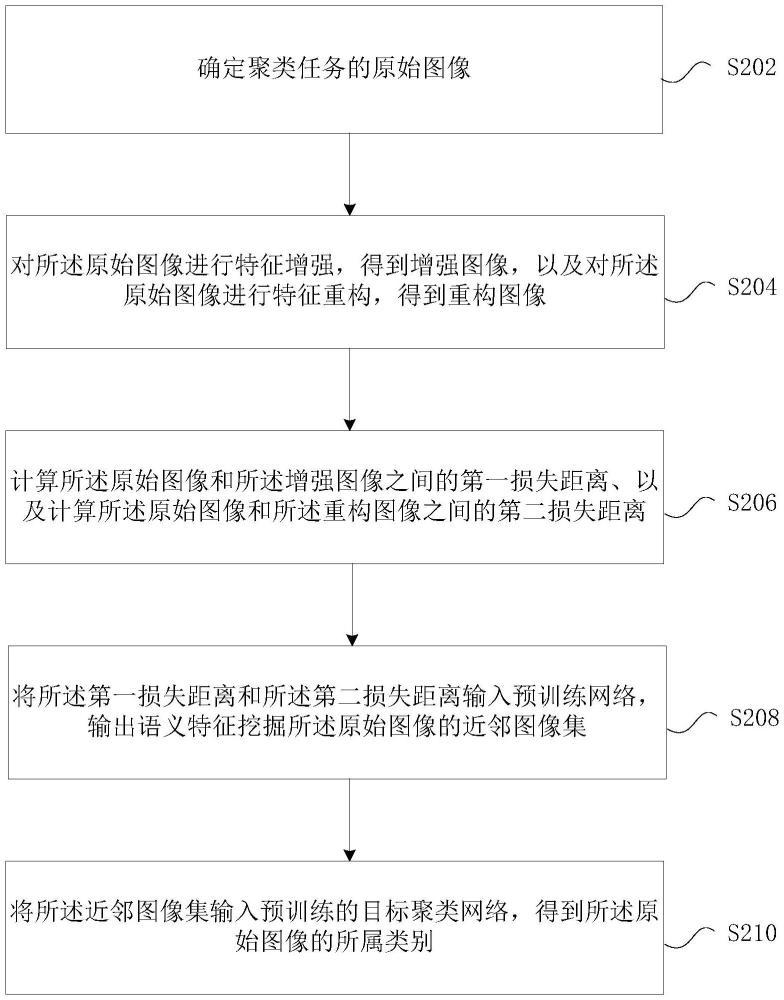
2、根據本發明的一個實施例,提供了一種基于語義的圖像聚類方法,包括:確定聚類任務的原始圖像;對所述原始圖像進行特征增強,得到增強圖像,以及對所述原始圖像進行特征重構,得到重構圖像;計算所述原始圖像和所述增強圖像之間的第一損失距離、以及計算所述原始圖像和所述重構圖像之間的第二損失距離;將所述第一損失距離和所述第二損失距離輸入預訓練網絡,輸出所述原始圖像的近鄰圖像集;將所述近鄰圖像集輸入預訓練的目標聚類網絡,得到所述原始圖像的所屬類別。
3、可選的,在將所述第一損失距離和所述第二損失距離輸入預訓練網絡之前,所述方法還包括:確定樣本圖像;對所述樣本圖像進行特征增強,得到增強樣本圖像,以及對所述樣本圖像進行特征重構,得到重構樣本圖像;計算所述樣本圖像和所述增強樣本圖像之間的第一損失距離、以及計算所述樣本圖像和所述重構樣本圖像之間的第二損失距離;采用所述第一損失距離和所述第二損失距離構建損失函數;基于所述樣本圖像和所述損失函數訓練得到預訓練網絡。
4、可選的,對所述樣本圖像進行特征重構,得到重構樣本圖像包括:確定與特征提取網絡的編碼器、以及與所述編碼器對應的解碼器;采用所述編碼器提取所述樣本圖像的圖像特征;采用所述解碼器對所述圖像特征進行重構,得到重構樣本圖像。
5、可選的,在將所述近鄰圖像集輸入預訓練的目標聚類網絡之前,所述方法還包括:針對樣本圖像集中的每個樣本圖像,通過近鄰算法構建對應樣本圖像的近鄰樣本集;采用所述樣本圖像和所述近鄰樣本集訓練得到目標聚類網絡。
6、可選的,采用所述樣本圖像和所述近鄰樣本集訓練得到目標聚類網絡包括:從所述近鄰樣本集中隨機選擇一個近鄰圖像;采用所述樣本圖像和所述近鄰圖像對初始聚類網絡進行更新,得到目標聚類網絡。
7、可選的,采用所述樣本圖像和所述近鄰圖像對初始聚類網絡進行更新,得到目標聚類網絡包括:計算所述樣本圖像和所述近鄰圖像之間的特征誤差;以所述特征誤差為損失函數對初始聚類網絡進行更新,得到目標聚類網絡。
8、可選的,以所述特征誤差為損失函數對初始聚類網絡進行更新,得到目標聚類網絡,包括:確定聚類集群m={1,...,c};采用以下損失函數l對初始聚類網絡進行更新,得到目標聚類網絡:
9、
10、其中,樣本x被分配到集群c的概率表示為,φη(x)為樣本x的預測概率,φη(k)為近鄰圖像的預測概率,φη(x)∈[0,1]m,x表示樣本圖像,|d|表示樣本數,k表示樣本圖像的近鄰圖像,nx表示樣本圖像的近鄰樣本集,c表示聚類數,<,>表示點積運算,δ是超參數。
11、根據本發明的另一個實施例,提供了一種基于語義的圖像聚類裝置,包括:第一確定模塊,用于確定聚類任務的原始圖像;處理模塊,用于對所述原始圖像進行特征增強,得到增強圖像,以及對所述原始圖像進行特征重構,得到重構圖像;計算模塊,用于計算所述原始圖像和所述增強圖像之間的第一損失距離、以及計算所述原始圖像和所述重構圖像之間的第二損失距離;挖掘模塊,用于將所述第一損失距離和所述第二損失距離輸入預訓練網絡,輸出所述原始圖像的近鄰圖像集;聚類模塊,用于將所述近鄰圖像集輸入預訓練的目標聚類網絡,得到所述原始圖像的所屬類別。
12、可選的,所述裝置還包括:第二確定模塊,用于在所述提取模塊將所述第一損失距離和所述第二損失距離輸入預訓練網絡之前,確定樣本圖像;處理模塊,用于對所述樣本圖像進行特征增強,得到增強樣本圖像,以及對所述樣本圖像進行特征重構,得到重構樣本圖像;計算模塊,用于計算所述樣本圖像和所述增強樣本圖像之間的第一損失距離、以及計算所述樣本圖像和所述重構樣本圖像之間的第二損失距離;第一構建模塊,用于采用所述第一損失距離和所述第二損失距離構建損失函數;第一訓練模塊,用于基于所述樣本圖像和所述損失函數訓練得到預訓練網絡。
13、可選的,所述處理模塊包括:確定單元,用于確定與特征提取網絡的編碼器、以及與所述編碼器對應的解碼器;提取單元,用于采用所述編碼器提取所述樣本圖像的圖像特征;重構單元,用于采用所述解碼器對所述圖像特征進行重構,得到重構樣本圖像。
14、可選的,所述裝置還包括:第二構建模塊,用于在所述聚類模塊將所述近鄰圖像集輸入預訓練的目標聚類網絡之前,針對樣本圖像集中的每個樣本圖像,通過近鄰算法構建對應樣本圖像的近鄰樣本集;第二訓練模塊,用于采用所述樣本圖像和所述近鄰樣本集訓練得到目標聚類網絡。
15、可選的,所述第二訓練模塊包括:選擇單元,用于從所述近鄰樣本集中隨機選擇一個近鄰圖像;更新單元,用于采用所述樣本圖像和所述近鄰圖像對初始聚類網絡進行更新,得到目標聚類網絡。
16、可選的,所述更新單元包括:計算子單元,用于計算所述樣本圖像和所述近鄰圖像之間的特征誤差;更新子單元,用于以所述特征誤差為損失函數對初始聚類網絡進行更新,得到目標聚類網絡。
17、可選的,所述更新子單元還用于:確定聚類集群m={1,...,c};采用以下損失函數l對初始聚類網絡進行更新,得到目標聚類網絡:
18、
19、
20、其中,樣本x被分配到集群c的概率表示為,φη(x)為樣本x的預測概率,φη(k)為近鄰圖像的預測概率,φη(x)∈[0,1]m,x表示樣本圖像,|d|表示樣本數,k表示樣本圖像的近鄰圖像,nx表示樣本圖像的近鄰樣本集,c表示聚類數,<,>表示點積運算,δ是超參數。
21、根據本技術實施例的另一方面,還提供了一種存儲介質,該存儲介質包括存儲的程序,程序運行時執行上述的步驟。
22、根據本技術實施例的另一方面,還提供了一種電子設備,包括處理器、通信接口、存儲器和通信總線,其中,處理器,通信接口,存儲器通過通信總線完成相互間的通信;其中:存儲器,用于存放計算機程序;處理器,用于通過運行存儲器上所存放的程序來執行上述方法中的步驟。
23、本技術實施例還提供了一種包含指令的計算機程序產品,當其在計算機上運行時,使得計算機執行上述方法中的步驟。
24、本發明的有益效果:
25、1、能夠在無需人類標注圖像類別的情況下建模當前任務的圖像特征,減少了人類標注的需要;
26、2.通過引入一種正則化損失,采用重構的方式增加表征與輸入之間的聯系,從而引入更多非共享的聚類任務相關信息,得到的圖像聚類結果更為準確;
27、3.在微調階段,拋棄了聚類算法與網絡同時更新的方式,而是采用圖像近鄰之間的相似性差異作為損失來更新聚類網絡,以更好地利用語義特征,得到的圖像聚類結果更為準確。
- 還沒有人留言評論。精彩留言會獲得點贊!