一種圖像主體自動識別系統及分割方法與流程
本發明涉及圖像數據處理,具體為一種圖像主體自動識別系統及分割方法。
背景技術:
1、隨著網絡技術的進步,網絡搜題隨之推廣開來,其技術概括來講就是通過終端設備(如手機、平板電腦等)采集試題信息,上傳至云端服務器,服務器對輸入信息進行分析處理,經過和數據庫中海量的習題資料比對后將匹配度高的結果返回至終端,完成搜題,其中對試題信息的采集普遍需要拍攝進行,因此需要圖像主體自動識別系統來識別圖片中的試題信息,并將試題信息分割出來。
2、現有的圖像主體自動識別系統通常是識別文字,并通過柵格方法來自動分割圖片區域,將試題信息分割出來,但由于大量試題文字普遍會密集的排列在一起,此種識別分割方法難以精準識別圖片中,學生所要搜索的是哪一部分題目,進而也無法針對性的將所需搜索部分分割出來,因此,根據上述問題提出一種圖像主體自動識別系統及分割方法。
技術實現思路
1、本發明的目的在于提供一種圖像主體自動識別系統及分割方法,以解決現有圖像主體自動識別系統難以從圖像的大量文字中,精準的識別出用戶所要搜索的是哪一部分題目,進而也無法針對性的將所需搜索部分分割出來的問題。
2、為實現上述目的,本發明提供如下技術方案:
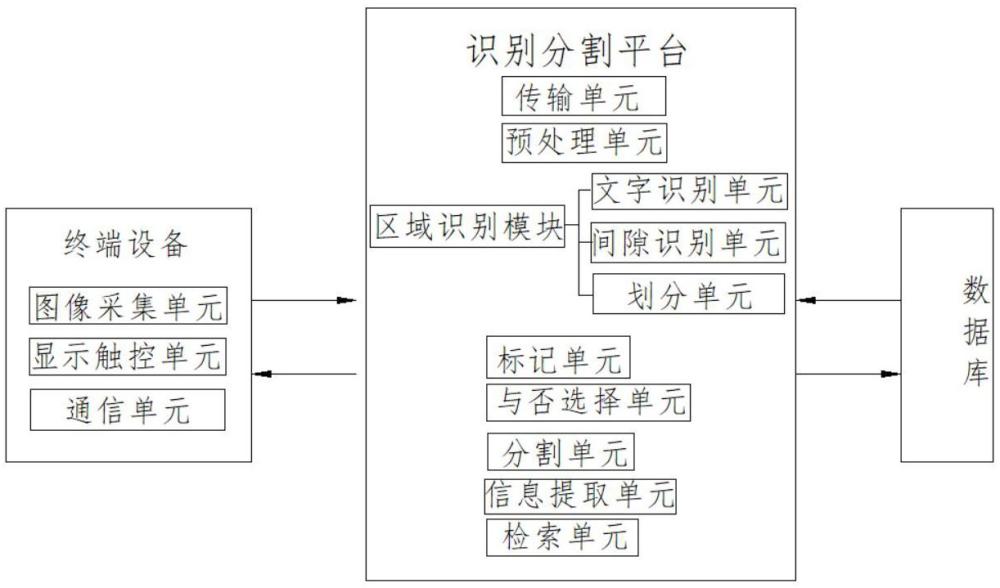
3、第一方面,本發明提供一種圖像主體自動識別系統,包括終端設備、識別分割平臺和數據庫;
4、所述終端設備為手持式電子設備,包括:
5、圖像采集單元,用于捕捉并轉換現實世界的圖像為數字信號;
6、顯示觸控單元,用于顯示圖像并接收用戶的觸控選擇指令;
7、通信單元,用于與所述識別分割平臺進行數據傳輸;
8、所述識別分割平臺包括:
9、傳輸單元,用于與終端設備及數據庫通信;
10、預處理單元,用于對圖像進行白平衡、亮度補償、灰度化及高分辨率銳化處理;
11、區域識別模塊,包括文字識別單元、間隙識別單元和劃分單元,所述文字識別單元用于識別文字段落首端的題目號,所述間隙識別單元用于分析段落間距差異,所述劃分單元基于題目號或間距特征劃分題目區域;
12、標記單元,用于對劃分后的區域進行標號框選并回傳至終端設備;
13、與否選擇單元,用于接收用戶選擇的標號并觸發分割指令;
14、分割單元,用于根據用戶選擇對非目標區域進行掩膜分割;
15、信息提取單元,采用ocr技術提取分割區域的文字信息;
16、檢索單元,用于將提取的題目信息與數據庫匹配并返回結果;
17、所述數據庫存儲習題資料,并通過傳輸單元與檢索單元連接。
18、第二方面,本發明另提供一種基于圖像主體自動識別系統的分割方法,包括以下步驟:
19、s1.?通過終端設備拍攝試題圖像,并傳輸至識別分割平臺;
20、s2.?對圖像執行預處理,包括基于直方圖均衡化的亮度補償、基于灰度世界假設的白平衡調整、灰度化及采用拉普拉斯算子的高分辨率銳化;
21、s3.?區域識別:
22、若檢測到文字段落首端存在題目號,通過模板匹配算法定位題目號,并以題目號為邊界劃分區域;
23、若無題目號,通過canny邊緣檢測提取文字行邊界,結合間隙識別單元的動態閾值算法計算段落間距,若間距大于預設閾值,則以該間隙為分界線劃分區域;
24、所述canny邊緣檢測的高斯濾波器標準差 σ為1.0,高閾值與低閾值的比值為3:1;
25、s4.?將劃分后的區域標號并回傳至終端設備,接收用戶選擇的標號;
26、s5.?分割處理:
27、基于用戶選擇生成二值掩膜,應用形態學閉運算填充孔洞;
28、采用分水嶺算法對掩膜區域進行精確分割,保留目標區域;
29、s6.?通過ocr函數提取分割區域的文字信息,并與數據庫進行相似度匹配,返回匹配結果。
30、進一步,步驟s2中所述基于直方圖均衡化的亮度補償,其均衡化函數為:;
31、其中,v為當前像素灰度值, ni為灰度級 i的像素數, n為總像素數, lmax為最大灰度級,默認 lmax=255。
32、進一步,所述的步驟s3?區域識別中的動態閾值算法公式為:
33、定義間距閾值 t= μ+ kσ,
34、其中 μ為平均間距, σ?為標準差, k?為經驗系數, k的取值范圍為1.2≤ k≤2.0,默認 k=1.5,用于區分題間間隙。
35、進一步,所述的步驟s5分割處理中的分水嶺算法,基于梯度圖像生成標記區域,通過淹沒模型分離粘連區域,函數表達式為:
36、watershed( igrad,markers)
37、其中 igrad為預處理后的梯度圖像,?markers為用戶選擇區域的初始標記。
38、進一步,步驟s5中所述形態學閉運算采用3×3矩形核,其結構元素定義為:;
39、且閉運算迭代次數為1次。
40、進一步,步驟s5中所述分水嶺算法的梯度圖像通過sobel算子計算,其水平與垂直梯度權重分別為:;
41、且梯度幅值計算為;其中 gx為水平梯度, gy為垂直梯度, g為梯度幅值。
42、進一步,所述的步驟s6中的ocr函數,采用卷積神經網絡cnn進行文字檢測,結合雙向lstm進行序列識別,輸出概率最高的文字序列。
43、進一步,所述的步驟s6中卷積神經網絡cnn進行文字檢測,采用resnet-50主干網絡:輸入圖像歸一化為32×256×332×256×3,經過resnet-50的卷積層提取多尺度特征;
44、輸出特征圖通過rpn生成候選框,rpn的錨點anchor設置為不同寬高比(0.5,?1,2),尺度為[8,16,32][8,16,32]像素;
45、非極大值抑制nms:篩選重疊候選框,抑制冗余檢測,閾值設為0.7,確保每個文字行僅保留一個最優候選框。
46、進一步,所述的步驟s6中序列識別,為雙向lstm與注意力機制:
47、使用雙向lstm網絡,包含2層隱藏層,每層隱藏單元數為256;lstm輸入為檢測模塊輸出的文字行圖像特征,特征提取通過roi?align層實現,輸出固定尺寸為8×328×32的特征圖;
48、結合注意力機制attention?mechanism,計算每個時間步的上下文向量,公式為:;
49、其中,為每個時間步的上下文向量, ht為lstm隱藏狀態,為上一時間步的上下文向量, wa為可訓練權重矩陣。
50、本發明的有益效果是:采用本發明一種圖像主體自動識別系統及分割方法具有以下優點:
51、高精度區域劃分:結合題目號檢測與動態間隙閾值,解決密集文字分割難題。
52、用戶交互優化:標號框選與觸控選擇機制,提升目標區域定位效率。
53、算法魯棒性:分水嶺算法與形態學閉運算結合,避免過分割或欠分割。
54、快速檢索:ocr模型與數據庫的高效匹配,實現秒級搜題響應。
- 還沒有人留言評論。精彩留言會獲得點贊!