一種適用于視頻內容識別的不確定性正未標注學習方法與流程
本發明涉及視頻內容識別,具體為一種適用于視頻內容識別的不確定性正未標注學習方法。
背景技術:
1、在當今數字化時代,視頻監控系統已廣泛應用于各個領域,如明廚亮灶監控、電梯安全監控以及公共場所異常行為檢測等,旨在保障安全、規范操作以及提供有效的管理依據。隨著視頻數據的海量增長,如何高效準確地對視頻內容進行識別成為了關鍵問題。
2、在視頻內容識別的研究領域中,正未標注學習(pulearning)方法因其能夠利用大量未標注數據輔助少量已標注正樣本進行模型訓練,逐漸成為研究熱點。傳統的正未標注學習方法,如兩步法,通常先對未標注樣本進行篩選或分類,再結合正樣本進行模型訓練。然而,這種方法往往難以準確區分未標注樣本中的正負樣本,容易導致模型學習到錯誤的信息,影響識別性能。
3、生成對抗網絡方法在pu學習中也有應用,通過生成器和判別器的對抗訓練來增強模型對未標注樣本的處理能力。但生成對抗網絡存在訓練不穩定、難以收斂等問題,且對計算資源要求較高,在實際應用中受到一定限制。
4、此外,在視頻內容識別任務中,由于視頻數據具有時序性和動態性的特點,現有的方法在處理這些特性時存在不足。一方面,單次預測的波動問題會影響模型對視頻內容的準確判斷;另一方面,模型難以有效捕捉視頻幀之間的動態時序信息,導致對視頻中復雜行為和狀態的識別能力有限。
5、同時,對于不同的視頻監控場景,如明廚亮灶監控中的規范操作識別、電梯安全監控中的正常狀態判斷以及公共場所異常行為檢測等,現有的方法缺乏足夠的適應性和靈活性,難以滿足多樣化的實際需求。而且,在模型部署后,面對不斷產生的新數據,缺乏有效的在線更新機制,無法及時利用新標注數據對模型進行優化,導致模型性能隨著時間推移逐漸下降。
6、綜上所述,現有的視頻內容識別方法在處理未標注樣本、捕捉時序信息、適應不同場景以及模型更新等方面存在諸多不足,因此,針對上述問題提出一種適用于視頻內容識別的不確定性正未標注學習方法。
技術實現思路
1、本發明的目的在于提供一種適用于視頻內容識別的不確定性正未標注學習方法,以解決上述背景技術中提出的問題。
2、為實現上述目的,本發明提供如下技術方案:
3、一種適用于視頻內容識別的不確定性正未標注學習方法,包括以下步驟:
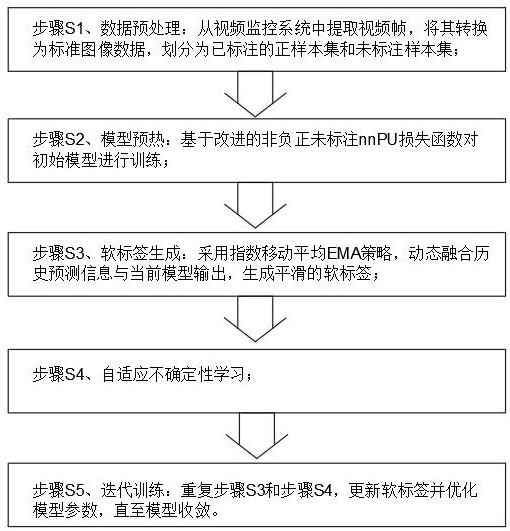
4、步驟s1、數據預處理:從視頻監控系統中提取視頻幀,將其轉換為標準圖像數據,劃分為已標注的正樣本集和未標注樣本集;
5、步驟s2、模型預熱:基于改進的非負正未標注nnpu損失函數對初始模型進行訓練,損失函數通過平衡正樣本與未標注樣本的貢獻,防止模型對未標注數據的過度負向偏置;
6、步驟s3、軟標簽生成:采用指數移動平均ema策略,動態融合歷史預測信息與當前模型輸出,生成平滑的軟標簽,公式為:,其中,為第次迭代時樣本的軟標簽,為權重參數,為第次迭代時樣本的軟標簽,為第次迭代的模型預測結果;
7、步驟s4、自適應不確定性學習:
8、不確定性權重生成:通過比較不同訓練階段的軟標簽差異,計算樣本不確定性分數,并基于徑向基函數核生成不確定性權重;
9、分段優化:根據軟標簽閾值將未標注樣本劃分為軟正樣本、軟負樣本和不確定樣本,分別設計加權損失函數進行優化;
10、步驟s5、迭代訓練:重復步驟s3和步驟s4,更新軟標簽并優化模型參數,直至模型收斂。
11、作為一種優選方案,步驟s2中改進的?nnpu?損失函數定義為:
12、,用于平衡正樣本與未標注樣本的梯度貢獻,其中,為改進的非負正未標注nnpu損失函數值,為正樣本的先驗概率,為正樣本數量,為未標注樣本數量,為交叉熵損失函數,為模型對第個正樣本的預測結果,為模型對第個未標注樣本的預測結果。
13、作為一種優選方案,步驟s4中不確定性分數的計算公式為:
14、,其中,為樣本的不確定性分數,為第次迭代時樣本的軟標簽,為第次迭代時樣本的軟標簽,且,。
15、作為一種優選方案,不確定性權重通過徑向基函數核生成,公式為:
16、,其中,為樣本的不確定性權重,為帶寬參數,取值范圍為0.05至0.3,用于調節不確定性權重的敏感度。
17、作為一種優選方案,步驟s4中分段優化的閾值設定為:
18、軟正樣本:,對應高置信正類樣本;
19、軟負樣本:,對應高置信負類樣本;
20、不確定樣本:.7,對應低置信樣本,需保守優化,其中,代表樣本的軟標簽。
21、作為一種優選方案,分段優化的總損失函數為:
22、,其中,為分段優化的總損失函數值,為軟正樣本的損失函數值,為軟負樣本的損失函數值,超參數,取值范圍為?0.3?至?0.7,用于調節不確定樣本的優化強度,為不確定樣本的損失函數值;
23、,用于強化軟正樣本學習,其中,為軟正樣本集的樣本數量,為模型對第個軟正樣本的預測結果,為第個軟正樣本的不確定性權重;
24、,用于強化軟負樣本學習,其中,為軟負樣本集的樣本數量;
25、,用于限制不確定樣本的負向梯度,其中,為不確定樣本集的樣本數量,為正樣本的先驗概率,為正樣本數量,為模型對第個正樣本的預測結果,為交叉熵損失函數。
26、作為一種優選方案,模型采用resnet-50作為主干網絡,末端替換為二分類全連接層,并通過全局平均池化層提取空間特征。
27、作為一種優選方案,迭代訓練階段的學習率采用自適應衰減策略,初始學習率為0.001,每訓練100個epoch衰減為原值的0.1倍,總訓練輪次不少于300次。
28、由上述本發明提供的技術方案可以看出,本發明提供的一種適用于視頻內容識別的不確定性正未標注學習方法,有益效果是:
29、提升模型預測穩定性:通過指數移動平均(ema)策略生成軟標簽,動態融合歷史預測信息與當前模型輸出,有效解決了單次預測波動問題,使模型對樣本類別的判斷更加穩定可靠,為后續的自適應不確定性學習提供了堅實基礎;
30、增強未標注樣本處理能力:基于軟標簽差異量化預測可靠性,通過計算不確定性分數并生成不確定性權重,結合分段優化策略,區分高/低置信樣本,能夠更合理地利用未標注樣本中的信息,降低噪聲干擾,提升模型在處理未標注樣本時的性能,從而在有限標注數據情況下也能實現高效學習;
31、平衡計算效率與模型性能:采用resnet-50作為主干網絡,結合自適應學習率策略,在保證模型具有強大特征提取能力的同時,合理控制計算資源消耗,使得模型在視頻內容識別任務中既能準確識別各類視頻內容,又能高效運行,滿足實際應用場景對計算效率和模型性能的雙重要求;
32、廣泛的場景適配性:適用于多種視頻監控場景,包括明廚亮灶監控、電梯安全監控、公共場所異常行為檢測等;支持對視頻幀的時序上下文特征提取,并具備模型部署后的在線更新機制,可通過增量學習動態融合新標注數據與歷史模型參數,能很好地適應動態變化的視頻監控環境,持續優化識別效果,保障不同場景下的監控任務高效完成。
- 還沒有人留言評論。精彩留言會獲得點贊!