基于深度學習的英語口語情感智能交互教學系統(tǒng)及方法
本發(fā)明涉及語音評測,尤其涉及基于深度學習的英語口語情感智能交互教學系統(tǒng)及方法。
背景技術(shù):
1、隨著信息技術(shù)和人工智能領(lǐng)域的深入發(fā)展,深度學習作為一種強大的機器學習技術(shù),已經(jīng)在語音識別、自然語言處理、情感分析等多個方面取得了突破。這些技術(shù)的發(fā)展為英語口語智能交互教學系統(tǒng)的構(gòu)建提供了堅實的基礎(chǔ),使得系統(tǒng)能夠理解和評估學習者的口語表達,包括語音準確性、語法正確性和情感表達。
2、現(xiàn)有技術(shù)中,英語口語智能交互教學系統(tǒng)通過聲學頻譜特征反應(yīng)聲音的頻率和振幅來評測英語發(fā)音是否失去爆破音。
3、例如公告號為:cn111916106b發(fā)明專利公開的一種提高英語教學中發(fā)音質(zhì)量的方法,包括:獲取用戶輸入的語音信息;對語音信息進行識別,獲取語音信息的特征參數(shù),并將特征參數(shù)向語音評估模型傳輸;語音評估模型,用于根據(jù)特征參數(shù)對語音信息進行評估,獲取語音評估結(jié)果;當語音評估結(jié)果為標準時,通過輸出設(shè)備提醒用戶發(fā)音標準;當語音評估結(jié)果為不標準時,獲取語音信息對應(yīng)的語音內(nèi)容,并將語音內(nèi)容向標準語音模型傳輸;標準語音模型,用于根據(jù)語音內(nèi)容,獲取標準語音信息,并通過輸出設(shè)備將標準語音信息輸出;將語音信息與標準語音信息進行比對,獲取相應(yīng)的語音指導信息;并通過輸出設(shè)備將語音指導信息向用戶傳輸,以輔助用戶進行發(fā)音訓練。
4、例如公告號為:cn113077822b發(fā)明專利公開的一種爆破音的評測方法、裝置、設(shè)備及存儲介質(zhì),包括:獲取待評測的英語語音;將所述英語語音送入解碼圖強制對齊進行識別,所述解碼圖包括帶爆破音的第一發(fā)音路徑和不帶爆破音的第二發(fā)音路徑;如果識別過程采用解碼圖中的第二發(fā)音路徑,則評測所述英語語音的發(fā)音失去爆破。
5、但本技術(shù)在實現(xiàn)本技術(shù)實施例中發(fā)明技術(shù)方案的過程中,發(fā)現(xiàn)上述技術(shù)至少存在如下技術(shù)問題:
6、現(xiàn)有技術(shù)中,由于在英語口語的智能交互過程中,用戶語音輸入的長句存在大量上下文協(xié)同發(fā)音變化,例如連讀、弱讀、失爆等,存在判斷上下文協(xié)同發(fā)音變化中失爆的準確性不足的問題。
技術(shù)實現(xiàn)思路
1、本技術(shù)實施例通過提供基于深度學習的英語口語情感智能交互教學系統(tǒng)及方法,解決了現(xiàn)有技術(shù)中判斷上下文協(xié)同發(fā)音變化中失爆的準確性不足的問題,實現(xiàn)了提高判斷上下文協(xié)同發(fā)音變化中失爆的準確性的效果。
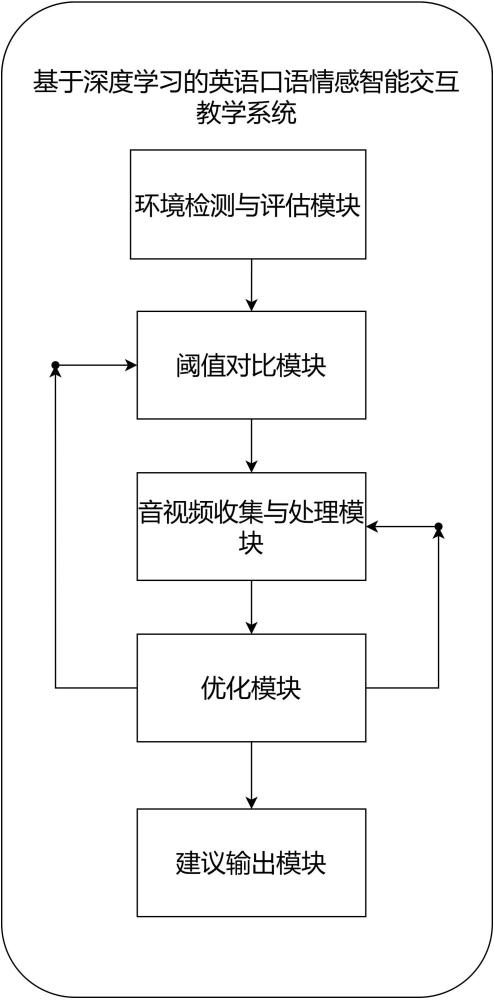
2、本技術(shù)實施例提供了基于深度學習的英語口語情感智能交互教學系統(tǒng)及方法,包括:環(huán)境檢測與評估模塊、閾值對比模塊、音視頻收集與處理模塊、優(yōu)化模塊和建議輸出模塊;所述環(huán)境檢測與評估模塊:用于對英語口語智能交互環(huán)境數(shù)據(jù)進行收集并評估,得到英語口語智能交互環(huán)境評估系數(shù),將英語口語智能交互環(huán)境評估系數(shù)傳輸至閾值對比模塊;所述閾值對比模塊:用于將環(huán)境檢測與評估模塊中得到的英語口語智能交互環(huán)境評估系數(shù)進行閾值范圍對比和圖像的參考閾值對比,將音視頻收集與處理模塊中得到的英語口語智能交互音頻的失爆判斷評估系數(shù)進行閾值對比;所述音視頻收集與處理模塊:用于對用戶輸入的英語口語智能交互音頻數(shù)據(jù)進行收集并評估,得到英語口語智能交互音頻的失爆判斷評估系數(shù),將英語口語智能交互音頻的失爆判斷評估系數(shù)傳輸至建議輸出模塊;所述優(yōu)化模塊:用于根據(jù)英語口語智能交互環(huán)境評估系數(shù)的閾值范圍對比結(jié)果對英語口語智能交互環(huán)境進行優(yōu)化,若優(yōu)化后的英語口語智能交互環(huán)境評估系數(shù)仍不通過閾值范圍對比,發(fā)送指令至音視頻收集與處理模塊,在收集英語口語智能交互音頻數(shù)據(jù)時同步收集英語口語智能交互唇形特征數(shù)據(jù),根據(jù)英語口語智能交互環(huán)境評估系數(shù)的閾值對比結(jié)果對英語口語智能交互唇形特征進行優(yōu)化;所述建議輸出模塊:用于根據(jù)英語口語智能交互音頻的失爆判斷評估系數(shù)輸出文本、音頻和可視化的英語口語糾錯建議。
3、進一步的,閾值對比模塊包括閾值范圍對比單元和圖像的參考閾值對比單元;所述閾值范圍對比單元:用于從數(shù)據(jù)庫中獲取英語口語智能交互環(huán)境評估系數(shù)的閾值范圍,將英語口語智能交互環(huán)境評估系數(shù)與英語口語智能交互環(huán)境評估系數(shù)的閾值范圍進行對比,若英語口語智能交互環(huán)境評估系數(shù)在英語口語智能交互環(huán)境評估系數(shù)的閾值范圍內(nèi),發(fā)送指令至音視頻收集與處理模塊,對用戶輸入的英語口語智能交互音頻數(shù)據(jù)進行收集并評估,得到英語口語智能交互音頻的失爆判斷評估系數(shù),若英語口語智能交互環(huán)境評估系數(shù)大于或等于英語口語智能交互環(huán)境評估系數(shù)的閾值范圍的最大值,發(fā)送指令至優(yōu)化模塊,對英語口語智能交互環(huán)境進行空間定位的動態(tài)權(quán)重分配,若英語口語智能交互環(huán)境評估系數(shù)小于英語口語智能交互環(huán)境評估系數(shù)的閾值范圍的最小值,發(fā)送指令至優(yōu)化模塊,對英語口語智能交互環(huán)境進行頻域信號處理,在空間定位的動態(tài)權(quán)重分配或頻域信號處理后,發(fā)送指令至環(huán)境檢測與評估模塊,重新進行英語口語智能交互環(huán)境數(shù)據(jù)的收集與評估,得到英語口語智能交互環(huán)境評估系數(shù),將英語口語智能交互環(huán)境評估系數(shù)傳輸至閾值對比模塊,若此時英語口語智能交互環(huán)境評估系數(shù)仍不在英語口語智能交互環(huán)境評估系數(shù)的閾值范圍內(nèi),發(fā)送指令至音視頻收集與處理模塊,在收集英語口語智能交互音頻數(shù)據(jù)時同步收集英語口語智能交互唇形特征數(shù)據(jù),將英語口語智能交互音頻數(shù)據(jù)與優(yōu)化后的英語口語智能交互唇形特征數(shù)據(jù)進行結(jié)合分析,得到英語口語智能交互音頻的失爆判斷評估系數(shù),若此時英語口語智能交互環(huán)境評估系數(shù)在英語口語智能交互環(huán)境評估系數(shù)的閾值范圍內(nèi),發(fā)送指令至音視頻收集與處理模塊,對用戶輸入的英語口語智能交互音頻數(shù)據(jù)進行收集并評估,得到英語口語智能交互音頻的失爆判斷評估系數(shù);所述圖像的參考閾值對比單元:用于從數(shù)據(jù)庫中獲取英語口語智能交互中圖像的銳度參考閾值,通過傳感器獲取英語口語智能交互中圖像的銳度,將英語口語智能交互中圖像的銳度與英語口語智能交互中圖像的銳度的參考閾值進行對比,若英語口語智能交互中圖像的銳度小于或等于英語口語智能交互中圖像的銳度參考閾值,發(fā)送指令至優(yōu)化模塊,對英語口語智能交互唇形特征數(shù)據(jù)進行優(yōu)化,將英語口語智能交互音頻數(shù)據(jù)與優(yōu)化后的英語口語智能交互唇形特征數(shù)據(jù)進行結(jié)合分析,得到英語口語智能交互音頻的失爆判斷評估系數(shù),若英語口語智能交互中圖像的銳度大于英語口語智能交互中圖像的銳度參考閾值,發(fā)送指令至音視頻收集與處理模塊,將英語口語智能交互音頻數(shù)據(jù)與英語口語智能交互唇形特征數(shù)據(jù)進行結(jié)合分析,得到英語口語智能交互音頻的失爆判斷評估系數(shù)。
4、進一步的,對英語口語智能交互環(huán)境數(shù)據(jù)進行收集的具體流程為:通過傳感器對英語口語智能交互環(huán)境數(shù)據(jù)進行收集,將英語口語智能交互環(huán)境數(shù)據(jù)進行預(yù)處理,得到預(yù)處理后的英語口語智能交互環(huán)境數(shù)據(jù),將預(yù)處理后的英語口語智能交互環(huán)境數(shù)據(jù)進行初步除噪;英語口語智能交互環(huán)境數(shù)據(jù)包括英語口語智能交互環(huán)境的噪聲聲壓級、英語口語智能交互環(huán)境的光照強度和英語口語智能交互環(huán)境的色溫。
5、進一步的,對用戶輸入的英語口語智能交互音頻數(shù)據(jù)進行收集的具體流程為:通過傳感器對英語口語智能交互音頻數(shù)據(jù)進行收集,將英語口語智能交互音頻數(shù)據(jù)進行預(yù)處理,得到預(yù)處理后的英語口語智能交互音頻數(shù)據(jù);英語口語智能交互音頻數(shù)據(jù)包括音頻的音素組合覆蓋率和音頻的瞬時能量峰值。
6、進一步的,英語口語智能交互環(huán)境評估系數(shù)的具體得到方法為:從數(shù)據(jù)庫獲取英語口語智能交互環(huán)境的噪聲聲壓級的權(quán)重因子、英語口語智能交互環(huán)境的光照強度的權(quán)重因子和英語口語智能交互環(huán)境的色溫的權(quán)重因子,將英語口語智能交互環(huán)境的噪聲聲壓級、英語口語智能交互環(huán)境的光照強度和英語口語智能交互環(huán)境的色溫按照時間序列排列,對英語口語智能交互環(huán)境的噪聲聲壓級、英語口語智能交互環(huán)境的光照強度和英語口語智能交互環(huán)境的色溫分配權(quán)重,對比每個時間序列點的英語口語智能交互環(huán)境的噪聲聲壓級、英語口語智能交互環(huán)境的光照強度和英語口語智能交互環(huán)境的色溫的標準值與英語口語智能交互環(huán)境的噪聲聲壓級、英語口語智能交互環(huán)境的光照強度和英語口語智能交互環(huán)境的色溫的實時值,均值化處理后得到英語口語智能交互環(huán)境評估系數(shù)。
7、進一步的,英語口語智能交互音頻的失爆判斷評估系數(shù)的具體得到方法為:若需要結(jié)合唇部特征數(shù)據(jù)時,從數(shù)據(jù)庫獲取嘴唇開合距離的權(quán)重因子、音頻的音素組合覆蓋率的權(quán)重因子和音頻的瞬時能量峰值的權(quán)重因子,為嘴唇開合距離與嘴唇開合距離參考值的偏差值、音頻的音素組合覆蓋率和音頻的瞬時能量峰值分配權(quán)重,將嘴唇開合距離、音頻的音素組合覆蓋率和音頻的瞬時能量峰值按照音素個數(shù)進行排序,將嘴唇開合距離與嘴唇開合距離參考值的偏差值、音頻的音素組合覆蓋率和音頻的瞬時能量峰值相結(jié)合并處理,得到英語口語智能交互音頻的失爆判斷評估系數(shù);若不需要結(jié)合唇部特征時,從數(shù)據(jù)庫獲取音頻的音素組合覆蓋率的權(quán)重因子和音頻的瞬時能量峰值的權(quán)重因子,為音頻的音素組合覆蓋率和音頻的瞬時能量峰值分配權(quán)重,將音頻的音素組合覆蓋率和音頻的瞬時能量峰值按照音素個數(shù)進行排序,將音頻的音素組合覆蓋率和音頻的瞬時能量峰值相結(jié)合并處理,得到英語口語智能交互音頻的失爆判斷評估系數(shù)。
8、進一步的,根據(jù)英語口語智能交互環(huán)境評估系數(shù)的閾值范圍對比結(jié)果對英語口語智能交互環(huán)境進行優(yōu)化的具體優(yōu)化步驟為:若英語口語智能交互環(huán)境評估系數(shù)大于或等于英語口語智能交互環(huán)境評估系數(shù)的閾值范圍的最大值,發(fā)送指令至優(yōu)化模塊,對英語口語智能交互環(huán)境進行空間定位的動態(tài)權(quán)重分配,若英語口語智能交互環(huán)境評估系數(shù)小于英語口語智能交互環(huán)境評估系數(shù)的閾值范圍的最小值,發(fā)送指令至優(yōu)化模塊,對英語口語智能交互環(huán)境進行頻域信號處理。
9、進一步的,在收集英語口語智能交互音頻數(shù)據(jù)時同步收集英語口語智能交互唇形特征數(shù)據(jù)的具體步驟為:通過深度傳感器獲取英語口語智能交互唇形數(shù)據(jù),通過深度學習模型提取英語口語智能交互唇形特征數(shù)據(jù),使用硬件觸發(fā)或軟件觸發(fā)同步音頻與視頻;英語口語智能交互唇形特征數(shù)據(jù)包括嘴唇開合距離;硬件觸發(fā)包括使用同步信號發(fā)生器發(fā)送脈沖信號,同時觸發(fā)音頻和視頻設(shè)備;軟件觸發(fā)包括通過ndi協(xié)議實現(xiàn)音視頻流時間戳對齊。
10、進一步的,根據(jù)英語口語智能交互音頻的失爆判斷評估系數(shù)輸出文本、音頻和可視化的英語口語糾錯建議的具體輸出方法:根據(jù)英語口語智能交互音頻的失爆判斷評估系數(shù)從數(shù)據(jù)庫中匹配預(yù)定義的文本、音頻和可視化的英語口語糾錯建議,文本、音頻和可視化的英語口語糾錯建議包括展示用戶發(fā)音和標準發(fā)音的聲譜圖、回放用戶英語口語錄音并高亮錯誤部位和指出發(fā)音錯誤類型并提供正確的文字發(fā)音實例。
11、進一步的,基于深度學習的英語口語情感智能交互教學方法為:對英語口語智能交互環(huán)境數(shù)據(jù)進行收集并評估,得到英語口語智能交互環(huán)境評估系數(shù),將英語口語智能交互環(huán)境評估系數(shù)傳輸至閾值對比模塊;將環(huán)境檢測與評估模塊中得到的英語口語智能交互環(huán)境評估系數(shù)進行閾值范圍對比和圖像的參考閾值對比,將音視頻收集與處理模塊中得到的英語口語智能交互音頻的失爆判斷評估系數(shù)進行閾值對比;對用戶輸入的英語口語智能交互音頻數(shù)據(jù)進行收集并評估,得到英語口語智能交互音頻的失爆判斷評估系數(shù),將英語口語智能交互音頻的失爆判斷評估系數(shù)傳輸至建議輸出模塊;根據(jù)英語口語智能交互環(huán)境評估系數(shù)的閾值范圍對比結(jié)果對英語口語智能交互環(huán)境進行優(yōu)化,若優(yōu)化后的英語口語智能交互環(huán)境評估系數(shù)仍不通過閾值范圍對比,發(fā)送指令至音視頻收集與處理模塊,在收集英語口語智能交互音頻數(shù)據(jù)時同步收集英語口語智能交互唇形特征數(shù)據(jù),根據(jù)英語口語智能交互環(huán)境評估系數(shù)的閾值對比結(jié)果對英語口語智能交互唇形特征進行優(yōu)化;根據(jù)英語口語智能交互音頻的失爆判斷評估系數(shù)輸出文本、音頻和可視化的英語口語糾錯建議。
12、本技術(shù)實施例中提供的一個或多個技術(shù)方案,至少具有如下技術(shù)效果或優(yōu)點:
13、1、通過對用戶輸入的英語口語智能交互音頻數(shù)據(jù)進行評估,得到英語口語智能交互音頻的失爆判斷評估系數(shù),從而根據(jù)英語口語智能交互音頻的失爆判斷評估系數(shù)輸出文本、音頻和可視化的英語口語糾錯建議,進而實現(xiàn)了提高判斷上下文協(xié)同發(fā)音變化中失爆的準確性的效果,有效解決了現(xiàn)有技術(shù)中,判斷上下文協(xié)同發(fā)音變化中失爆的準確性不足的問題。
14、2、通過在收集英語口語智能交互音頻數(shù)據(jù)時同步收集英語口語智能交互唇形特征數(shù)據(jù),從而根據(jù)英語口語智能交互環(huán)境評估系數(shù)的閾值對比結(jié)果對英語口語智能交互唇形特征進行優(yōu)化,進而實現(xiàn)了增強基于深度學習的英語口語情感智能交互教學系統(tǒng)的多模態(tài)學習體驗,有效解決了現(xiàn)有技術(shù)中,基于深度學習的英語口語情感智能交互教學系統(tǒng)的多模態(tài)學習體驗不足的問題。
15、3、通過將環(huán)境檢測與評估模塊中得到的英語口語智能交互環(huán)境評估系數(shù)進行閾值范圍對比,從而根據(jù)英語口語智能交互環(huán)境評估系數(shù)的閾值范圍對比結(jié)果對英語口語智能交互環(huán)境進行優(yōu)化,進而實現(xiàn)了提高基于深度學習的英語口語情感智能交互教學系統(tǒng)的環(huán)境適用性,有效解決了現(xiàn)有技術(shù)中,基于深度學習的英語口語情感智能交互教學系統(tǒng)的環(huán)境適用性不足的問題。
- 還沒有人留言評論。精彩留言會獲得點贊!