課程文件的生成方法、裝置、終端設備和存儲介質(zhì)與流程
本技術涉及計算機,并且更具體地,涉及計算機中一種課程文件的生成方法、課程文件的生成裝置、終端設備和計算機可讀存儲介質(zhì)。
背景技術:
1、隨著人工智能的不斷發(fā)展,傳統(tǒng)的教學方式也在不斷發(fā)展,出現(xiàn)了網(wǎng)上授課的方式;例如,微課視頻;微課視頻由于自身具備的靈活性和重復觀看的特點,受到了學生的喜愛。為了提高學生通過微課學習的質(zhì)量和效率,可以向微課視頻中增加字幕,提高老師對課程講解的可讀性。
2、相關技術中,在微課視頻錄制完成后,可以在微課視頻中添加相應的講解字幕;目前,微課視頻中講解字幕的準確性較低。因此,如何提高微課視頻中字幕的準確性成為了亟需解決的問題。
技術實現(xiàn)思路
1、本技術提供了一種課程文件的生成方法、課程文件的生成裝置、終端設備和計算機可讀存儲介質(zhì),該方法能夠提高微課視頻中字幕的準確性。
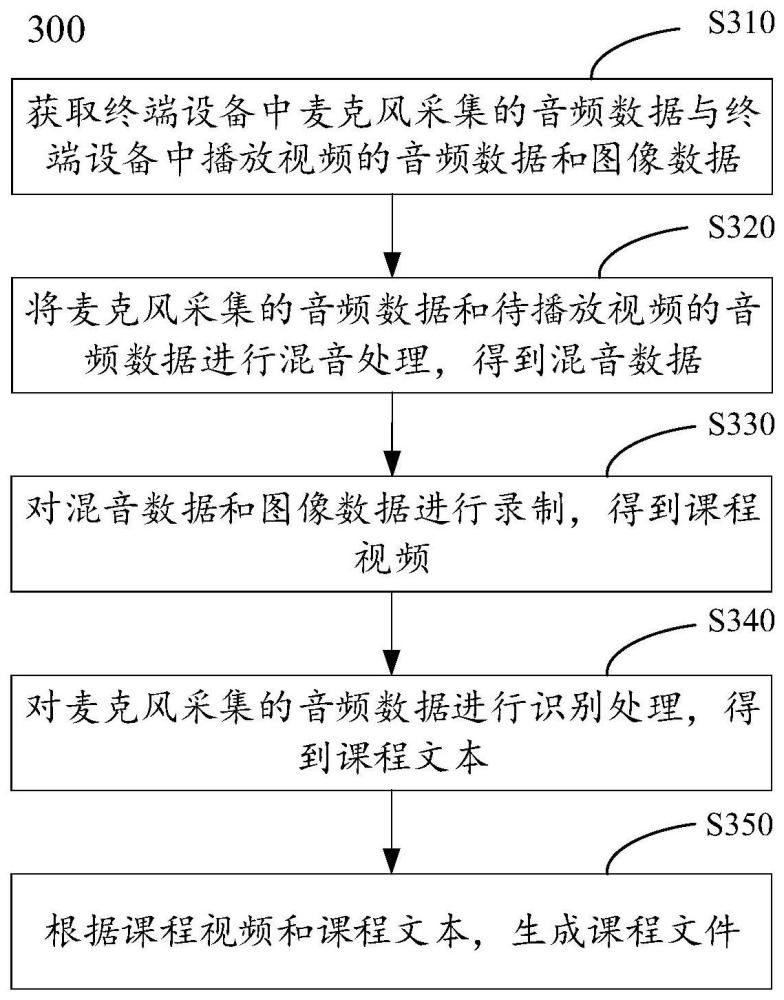
2、第一方面,提供了一種課程文件的生成方法,該方法包括:獲取終端設備中麥克風采集的音頻數(shù)據(jù)與終端設備中播放視頻的音頻數(shù)據(jù)和圖像數(shù)據(jù),其中,麥克風采集的音頻數(shù)據(jù)中不包括播放視頻的音頻數(shù)據(jù);將麥克風采集的音頻數(shù)據(jù)和播放視頻的音頻數(shù)據(jù)進行混音處理,得到混音數(shù)據(jù),其中,混音處理用于對麥克風采集的音頻數(shù)據(jù)和播放視頻的音頻數(shù)據(jù)進行整合,混音數(shù)據(jù)中包括麥克風采集的音頻數(shù)據(jù)和播放視頻的音頻數(shù)據(jù);對混音數(shù)據(jù)和圖像數(shù)據(jù)進行錄制,得到課程視頻;對麥克風采集的音頻數(shù)據(jù)進行識別處理,得到課程文本;根據(jù)課程視頻和課程文本,生成課程文件。
3、在本技術的實施例中,在生成課程文件(即微課視頻)的過程中,通過對麥克風采集的音頻數(shù)據(jù)和終端設備中播放視頻的音頻數(shù)據(jù)進行混音處理得到混音數(shù)據(jù),并對混音數(shù)據(jù)和終端的圖像數(shù)據(jù)錄制得到對應的課程視頻;由于麥克風采集的音頻數(shù)據(jù)中不包括播放視頻的音頻數(shù)據(jù),因此在對麥克風采集的音頻數(shù)據(jù)進行識別產(chǎn)生的文本時,并不會識別終端設備中播放視頻的音頻數(shù)據(jù),使終端設備中播放視頻的音頻數(shù)據(jù)不會對麥克風采集的音頻數(shù)據(jù)識別出的文本產(chǎn)生干擾,從而使得識別出的課程文本僅包括麥克風采集的音頻數(shù)據(jù)對應的文本,而不包括終端設備中播放視頻的音頻數(shù)據(jù)對應的文本,從而提高了微課視頻中字幕的準確性。
4、結合第一方面,在第一方面的某些實現(xiàn)方式中,該方法還包括:在獲取終端設備中麥克風采集的音頻數(shù)據(jù)之后,還包括:對麥克風采集的音頻數(shù)據(jù)進行拷貝處理,得到第一數(shù)據(jù)和第二數(shù)據(jù),其中,第一數(shù)據(jù)和第二數(shù)據(jù)相同;將麥克風采集的音頻數(shù)據(jù)和播放視頻的音頻數(shù)據(jù)進行混音處理,得到混音數(shù)據(jù),包括:將第一數(shù)據(jù)和播放視頻的音頻數(shù)據(jù)進行混音處理,得到混音數(shù)據(jù);以及,對麥克風采集的音頻數(shù)據(jù)進行識別處理,得到課程文本,包括:對第二數(shù)據(jù)進行識別處理,得到課程文本;其中,混音處理和識別處理同步進行。
5、在本技術的實施例中,通過對麥克風采集的音頻數(shù)據(jù)復制處理后得到相同的兩個音頻數(shù)據(jù)(即第一數(shù)據(jù)和第二數(shù)據(jù)),可以實現(xiàn)在對第一數(shù)據(jù)和播放視頻的音頻數(shù)據(jù)進行混音處理時,同時還對第二數(shù)據(jù)進行識別處理,從而同步進行生成課程視頻和課程文字的過程,提高了課程文件中字幕生成的實時性。
6、結合第一方面和上述實現(xiàn)方式,在第一方面的某些實現(xiàn)方式中,對第二數(shù)據(jù)進行識別處理,該方法包括:獲取第二數(shù)據(jù)中的虛詞;去除第二數(shù)據(jù)中的虛詞;對去除虛詞的第二數(shù)據(jù)進行識別處理。
7、在本技術的實施例中,由于在對第二數(shù)據(jù)進行識別處理時,去除了第二數(shù)據(jù)中的虛詞,可以使進行識別的第二數(shù)據(jù)中不存在虛詞,僅包括與課程相關的講解文字,從而進一步的提高了課程文件中字幕的準確性。
8、結合第一方面和上述實現(xiàn)方式,在第一方面的某些實現(xiàn)方式中,該方法還包括:去除課程文本中的虛詞,得到目標文本;根據(jù)課程視頻和課程文本,生成課程文件,包括:根據(jù)目標文本和課程視頻,生成課程文件。
9、在本技術的實施例中,通過去除課程文本的虛詞,使得去除虛詞的目標文本中僅包含與課程相關的講解文字,從而可以進一步提高課程文件中字幕的準確性。
10、結合第一方面和上述實現(xiàn)方式,在第一方面的某些實現(xiàn)方式中,課程文件中包括多個課程子文件,課程文本中包括多個課程子文本,課程視頻中包括多個課程子視頻;根據(jù)課程視頻和課程文本,生成課程文件,該方法包括:對課程文本進行分段處理,得到多個課程子文本;根據(jù)多個課程子文本,對課程視頻進行剪輯處理,得到多個課程子視頻;根據(jù)多個課程子文本和多個課程子視頻,生成多個課程子文件。
11、在本技術的實施例中,可以根據(jù)多個課程子文本和多個課程子視頻,生成多個課程子文件;由于可以基于課程子文本和課程子文本對應的課程子視頻對應生成課程子文件,使生成的課程文件可以滿足用戶的聽課需求或者針對課程重點內(nèi)容進行剪輯,提高課程子文件生成的靈活性。
12、結合第一方面和上述實現(xiàn)方式,在第一方面的某些實現(xiàn)方式中,該方法還包括:檢測課程文本的多個分詞的排序是否符合預設排序條件;若檢測到多個分詞的排序不符合預設排序條件,將多個分詞的排序調(diào)節(jié)至符合預設排序條件;或者,若檢測到多個分詞的排序不符合預設排序條件,向用戶發(fā)送提醒信息,使用戶根據(jù)提醒信息將多個分詞的排序調(diào)節(jié)至符合預設排序條件;其中,提醒信息用于提示用戶多個分詞的排序不符合預設排序條件。
13、在本技術的實施例中,若檢測到多個分詞的排序不符合預設排序條件,可以將多個分詞的排序調(diào)節(jié)至符合預設排序條件,即在多個分詞的排序錯亂時,將錯亂的排序調(diào)節(jié)為正確的排序,從而使得閱讀課程文本中的語句可以更加通順,進一步提高了微課視頻中字幕的準確性。
14、結合第一方面和上述實現(xiàn)方式,在第一方面的某些實現(xiàn)方式中,獲取終端設備中麥克風采集的音頻數(shù)據(jù),該方法包括:按照預設時長獲取麥克風采集的音頻數(shù)據(jù);或者,按照預設頁碼間隔獲取麥克風采集的音頻數(shù)據(jù),其中,預設頁碼間隔是通過圖像數(shù)據(jù)的大小確定的。
15、在本技術的實施例中,按照預設時長或者預設頁碼間隔獲取麥克風采集的音頻數(shù)據(jù),可以避免在課程視頻錄制完成后,再統(tǒng)一獲取麥克風采集的音量數(shù)據(jù),容易造成音頻數(shù)據(jù)量過大,降低識別音頻數(shù)據(jù)的速度;因此,按照預設時長或者預設頁碼間隔獲取麥克風采集的音頻數(shù)據(jù),可以使得每次識別音頻數(shù)據(jù)時的處理量較小,從而提高識別音頻數(shù)據(jù)的效率。
16、結合第一方面和上述實現(xiàn)方式,在第一方面的某些實現(xiàn)方式中,該方法還包括:對第二數(shù)據(jù)進行重采樣處理。
17、在本技術的實施例中,可以對第二數(shù)據(jù)進行重采樣處理,使得進行重采樣處理后的第二數(shù)據(jù)的采樣率降低,更適合快速語音識別場景;由于通過重采樣降低了第二數(shù)據(jù)的大小,使得對第二數(shù)據(jù)的識別更快,從而提高了微課視頻中字幕的生成效率。
18、結合第一方面和上述實現(xiàn)方式,在第一方面的某些實現(xiàn)方式中,根據(jù)課程視頻和課程文本,生成課程文件,該方法包括:獲取麥克風采集的音頻數(shù)據(jù)的第一時間戳,和獲取混音數(shù)據(jù)的第二時間戳;確定第一時間戳和第二時間戳的差值;根據(jù)差值控制麥克風采集的音頻數(shù)據(jù)和混音數(shù)據(jù)進行對齊處理;根據(jù)圖像數(shù)據(jù)、課程文本和對齊處理后的混音數(shù)據(jù),生成課程文件。
19、在本技術的實施例中,將麥克風采集的音頻數(shù)據(jù)和混音數(shù)據(jù)進行對齊處理后,可以說明麥克風采集的音頻數(shù)據(jù)和混音數(shù)據(jù)的時間軸是一一對應的,由于混音數(shù)據(jù)和終端設備播放視頻中的圖像數(shù)據(jù)是同時錄制的,進而可以說明終端設備播放視頻中的圖像數(shù)據(jù)、課程文本和對齊處理后的混音數(shù)據(jù)的時間軸也是一一對應的,從而可以確保課程文件中的圖像數(shù)據(jù)、音頻數(shù)據(jù)和字幕的時間是同步的,避免了課程文件中圖像數(shù)據(jù)、音頻數(shù)據(jù)和字幕不同步的可能。
20、第二方面,提供了一種課程文件的生成裝置,該裝置包括:獲取模塊:用于獲取終端設備中麥克風采集的音頻數(shù)據(jù)與終端設備中播放視頻的音頻數(shù)據(jù)和圖像數(shù)據(jù),其中,麥克風采集的音頻數(shù)據(jù)中不包括播放視頻的音頻數(shù)據(jù);混音模塊:用于將麥克風采集的音頻數(shù)據(jù)和播放視頻的音頻數(shù)據(jù)進行混音處理,得到混音數(shù)據(jù),其中,混音處理用于對麥克風采集的音頻數(shù)據(jù)和播放視頻的音頻數(shù)據(jù)進行整合,混音數(shù)據(jù)中包括麥克風采集的音頻數(shù)據(jù)和播放視頻的音頻數(shù)據(jù);錄制模塊:用于對混音數(shù)據(jù)和圖像數(shù)據(jù)進行錄制,得到課程視頻;識別模塊:用于對麥克風采集的音頻數(shù)據(jù)進行識別處理,得到課程文本;生成模塊:用于根據(jù)課程視頻和課程文本,生成課程文件。
21、結合第二方面,在第二方面的某些實現(xiàn)方式中,該裝置還包括:拷貝模塊,在獲取終端設備中麥克風采集的音頻數(shù)據(jù)之后,拷貝模塊用于對麥克風采集的音頻數(shù)據(jù)進行拷貝處理,得到第一數(shù)據(jù)和第二數(shù)據(jù),其中,第一數(shù)據(jù)和第二數(shù)據(jù)相同;將麥克風采集的音頻數(shù)據(jù)和播放視頻的音頻數(shù)據(jù)進行混音處理,得到混音數(shù)據(jù),混音模塊具體用于:將第一數(shù)據(jù)和播放視頻的音頻數(shù)據(jù)進行混音處理,得到混音數(shù)據(jù);以及,對麥克風采集的音頻數(shù)據(jù)進行識別處理,得到課程文本,識別模塊具體用于對第二數(shù)據(jù)進行識別處理,得到課程文本;其中,混音處理和識別處理同步進行。
22、結合第二方面和上述實現(xiàn)方式,在第二方面的某些實現(xiàn)方式中,對第二數(shù)據(jù)進行識別處理,識別模塊具體用于:獲取第二數(shù)據(jù)中的虛詞;去除第二數(shù)據(jù)中的虛詞;對去除虛詞的第二數(shù)據(jù)進行識別處理。
23、結合第二方面和上述實現(xiàn)方式,在第二方面的某些實現(xiàn)方式中,該裝置還包括:去除模塊,用于去除課程文本中的虛詞,得到目標文本;根據(jù)課程視頻和課程文本,生成課程文件,生成模塊具體用于:根據(jù)目標文本和課程視頻,生成課程文件。
24、結合第二方面和上述實現(xiàn)方式,在第二方面的某些實現(xiàn)方式中,課程文件中包括多個課程子文件,課程文本中包括多個課程子文本,課程視頻中包括多個課程子視頻;根據(jù)課程視頻和課程文本,生成課程文件,生成模塊具體用于:對課程文本進行分段處理,得到多個課程子文本;根據(jù)多個課程子文本,對課程視頻進行剪輯處理,得到多個課程子視頻;根據(jù)多個課程子文本和多個課程子視頻,生成多個課程子文件。
25、結合第二方面和上述實現(xiàn)方式,在第二方面的某些實現(xiàn)方式中,該裝置還包括:檢測模塊,用于檢測課程文本的多個分詞的排序是否符合預設排序條件;若檢測到多個分詞的排序不符合預設排序條件,將多個分詞的排序調(diào)節(jié)至符合預設排序條件;或者,若檢測到多個分詞的排序不符合預設排序條件,向用戶發(fā)送提醒信息,使用戶根據(jù)提醒信息將多個分詞的排序調(diào)節(jié)至符合預設排序條件;其中,提醒信息用于提示用戶多個分詞的排序不符合預設排序條件。
26、結合第二方面和上述實現(xiàn)方式,在第二方面的某些實現(xiàn)方式中,獲取終端設備中麥克風采集的音頻數(shù)據(jù),獲取模塊具體用于:按照預設時長獲取麥克風采集的音頻數(shù)據(jù);或者,按照預設頁碼間隔獲取麥克風采集的音頻數(shù)據(jù),其中,預設頁碼間隔是通過圖像數(shù)據(jù)的大小確定的。
27、結合第二方面和上述實現(xiàn)方式,在第二方面的某些實現(xiàn)方式中,該裝置還包括:重采樣模塊,用于對第二數(shù)據(jù)進行重采樣處理。
28、結合第二方面和上述實現(xiàn)方式,在第二方面的某些實現(xiàn)方式中,根據(jù)課程視頻和課程文本,生成課程文件,生成模塊具體用于:獲取麥克風采集的音頻數(shù)據(jù)的第一時間戳,和獲取混音數(shù)據(jù)的第二時間戳;確定第一時間戳和第二時間戳的差值;根據(jù)差值控制麥克風采集的音頻數(shù)據(jù)和混音數(shù)據(jù)進行對齊處理;根據(jù)圖像數(shù)據(jù)、課程文本和對齊處理后的混音數(shù)據(jù),生成課程文件。
29、第三方面,提供一種終端設備,包括存儲器和處理器。該存儲器用于存儲可執(zhí)行程序代碼,該處理器用于從存儲器中調(diào)用并運行該可執(zhí)行程序代碼,使得該終端設備執(zhí)行上述第一方面或第一方面任意一種可能的實現(xiàn)方式中的方法。
30、第四方面,提供了一種計算機程序產(chǎn)品,該計算機程序產(chǎn)品包括:計算機程序代碼,當該計算機程序代碼在計算機上運行時,使得該計算機執(zhí)行上述第一方面或第一方面任意一種可能的實現(xiàn)方式中的方法。
31、第五方面,提供了一種計算機可讀存儲介質(zhì),該計算機可讀存儲介質(zhì)存儲有計算機程序代碼,當該計算機程序代碼在計算機上運行時,使得該計算機執(zhí)行上述第一方面或第一方面任意一種可能的實現(xiàn)方式中的方法。
- 還沒有人留言評論。精彩留言會獲得點贊!