一種面向有限數據的半監督滾動軸承跨域故障診斷方法
本發明涉及故障診斷,尤其涉及一種面向有限數據的半監督滾動軸承跨域故障診斷方法。
背景技術:
1、滾動軸承是旋轉機械的關鍵部件,在電力、化工等諸多工業領域廣泛應用,其運行狀況對生產系統的穩定、安全與高效意義非凡。由于長期處于高速、復雜受力與多變工況中,滾動軸承易因疲勞、磨損等出現故障。若故障未被及時發現,輕微時會使機械振動、噪音增加、降低效率,提高能耗與成本;嚴重時則可能引發設備停機,中斷生產,造成巨大經濟損失,甚至引發安全事故。而精確的故障診斷能實時監測其狀態,提前察覺潛在隱患,以便及時采取維護舉措,如規劃檢修、更換部件等。因此對滾動軸承進行故障診斷是非常有必要的。旋轉部件不會一直運行在固定的工況下,會出現不同程度的設備磨損和退化情況,這種問題的出現阻礙了基于深度學習的故障診斷方法在實際生產環境中的廣泛應用。變工況導致的直接結果就是數據的分布存在差異,進而導致模型可能出現在源域上效果較好但目標域效果較差的問題。因此,如何解決測試數據和訓練數據分布偏移帶來的泛化性能降低是一個挑戰。此外,基于深度學習的故障診斷方法需要在訓練階段使用大量有標記數據,才能保證模型的學習效果。但是在實際生產環境中,故障數據的收集以及打標簽的工作比較繁瑣,需要較多人工參與,因此當所需樣本數、源域數較多時,數據標記需要耗費大量人力。因此,如何在只有部分數據有標簽的情況下訓練模型,同時保證模型的可靠性是一個關鍵的挑戰。最近,基于領域泛化方法的出現被用來解決訓練數據和測試數據分布偏移的問題。其核心思想就是通過匹配不同域樣本在高維空間中的特征分布,同時提取每類樣本的域不變特征來消除跨域分布差異。這些方法已經被證實能夠在領域泛化的故障診斷研究中取得比較好的效果。然而,這些研究大部分都是假設用于訓練模型的故障數據集中各個域的樣本都是有標簽的,而鑒于人工成本,這種假設并不一定成立,即源域中會包含部分無標簽的數據。無標簽的數據的存在就會導致基于深度學習的模型無法正常進行訓練。
技術實現思路
1、針對上述問題,本發明針對性地提出一種面向有限數據的半監督滾動軸承跨域故障診斷方法。其主要思想是,既能夠給無標簽數據打上偽標簽,同時能夠保證偽標簽的可靠性,又能學習每類故障的域不變特征。
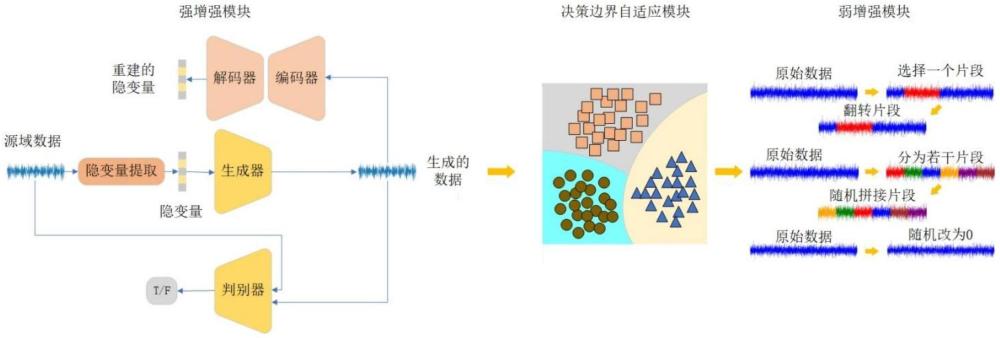
2、本發明的技術方案如下:一種面向有限數據的半監督滾動軸承跨域故障診斷方法,源域有標簽數據經強增強模塊進行數據增強,生成強增強數據所述強增強數據和源域有標簽數據經決策邊界自適應模塊獲得決策邊界;根據決策邊界為源域無標簽數據確定其偽標簽對于源域有標簽數據進行弱增強,得到弱增強數據根據弱增強數據計算初始置信度,并生成置信度閾值;根據所述置信度閾值對源域無標簽數據的偽標簽進行標簽篩選,得到純化數據設計語義對齊模塊和健康狀態分類模塊構建網絡模型,將純化后的有標簽數據輸入到網絡模型中進行訓練,得到可用于診斷的網絡模型。之后使用時,待檢測數據直接輸入至訓練完成的網絡模型中。
3、所述強增強模塊包括隱變量提取模塊、生成對抗網絡gan和變分自編碼器vae;隱變量提取模塊、gan的生成器和判別器均由殘差卷積模塊組成,vae的編碼器和解碼器由若干深度卷積神經網絡模塊組成;隱變量提取模塊首個卷積層使用16×1的卷積核,用于提取短時特征,輔助模型自動學習故障相關特征,同時去除與故障無關的特征;其余卷積層均采用3×1的卷積核;每層卷積層之后均經過批量歸一化操作、激活操作和最大值池化操作;所述隱變量提取模塊的輸出,使用flatten操作,將提取的特征展開至一維特征表示作為隱變量xl,并作為生成器的輸入;gan的生成器將提取到的隱變量經過若干殘差卷積操作后產生一個與源域數據尺寸相同的樣本,記作gan的判別器將原始樣本x和作為輸入,對兩者進行區分,輸出當前輸入的樣本是否為真實樣本;所述gan的判別器輸入層采用大卷積核,后續若干層采用3×1的卷積核;變分自編碼器vae針對生成數據進行隱變量提取,并將提取到的隱變量與針對原始數據提取到的隱變量xl計算其差異,并最小化該差異,以降低數據生成過程中信息丟失情況。
4、所述決策邊界自適應模塊采用基于k-means的聚類方法學習樣本決策邊界;通過最大化樣本平均熵來優化決策邊界。
5、所述源域無標簽數據確定其偽標簽,具體為,將樣本映射至高維空間,并根據最優決策邊界計算樣本與聚簇中心之間的歐式距離,將距離最小的聚簇中心對應的類別標簽賦給樣本得到樣本的偽標簽
6、所述弱增強模塊,涉及三種增強方式:
7、1)翻轉,將輸入數據中的隨機一段數據進行前后順序翻轉;
8、2)拼接,將輸入數據劃分為若干段,并進行亂序拼接;
9、3)mask,將輸入數據中若干隨機位置的數據置為0;
10、將源域有標簽數據進行弱增強,得到弱增強數據弱增強數據出現偏離原始源域有標簽數據情況,將多個源域之間的域偏移情況作為預測置信度的權重,同時參與到偽標簽篩選的閾值計算中;弱增強后每個樣本的預測置信度通過高斯核函數計算得到,高斯核函數為k(x,y)=exp{-||x-y||2/2σ2};對于數據點di,計算與同一簇中其他數據點的相似度之和為相對于整個數據集的相似度之和為數據點di的預測置信度為其中域偏移量引入指數函數保持其單調遞增,計算公式為其中a為超參數,di為樣本di相對于其他源域和目標域的距離,將調整后的域偏移量作為權重,與預測置信度相結合來生成新的置信度值,得到樣本純化的置信度閾值其中篩除偽標簽所屬類別概率小于置信度閾值的樣本,得到純化數據。
11、所述語義對齊模塊輸入為源域有標簽數據強增強數據和經偽標簽篩選后的純化數據經過卷積網絡映射至高維空間后,學習跨域不變特征,得到高維特征z,并將z輸入至健康狀態分類模塊,得到模型的預測輸出結果。
12、所述原始數據中有一個域有標簽,其余若干域無標簽。
13、本發明的有益效果:本發明提出一種面向有限數據的半監督滾動軸承跨域故障診斷方法,主要基于強增強模塊、決策邊界自適應模塊、弱增強模塊、語義對齊模塊和健康狀態分類模塊實現。首先,使用強增強模塊用于實現對樣本的強增強;然后,使用強增強得到的樣本進行決策邊界自適應調整,獲得決策邊界;根據決策邊界為源域無標簽數據確定其偽標簽;對于源域有標簽數據進行弱增強,得到弱增強數據;根據弱增強數據計算初始置信度,并生成置信度閾值;根軍所述置信度閾值對源域無標簽數據的偽標簽進行標簽篩選,得到純化數據;設計語義對齊模塊和健康狀態分類模塊構建網絡模型,將純化后的有標簽數據輸入到網絡模型中進行訓練,得到可用于診斷的模型。總體來說,本發明所提出的方法既解決了跨域故障診斷中巨大分布差異對模型訓練帶來的問題,又解決了如何在有限有標記數據下訓練模型的問題。
技術特征:
1.一種面向有限數據的半監督滾動軸承跨域故障診斷方法,其特征在于,源域有標簽數據經強增強模塊進行數據增強,生成強增強數據所述強增強數據和源域有標簽數據經決策邊界自適應模塊獲得決策邊界;根據決策邊界為源域無標簽數據確定其偽標簽對于源域有標簽數據進行弱增強,得到弱增強數據根據弱增強數據計算初始置信度,并生成置信度閾值;根據所述置信度閾值對源域無標簽數據的偽標簽進行標簽篩選,得到純化數據設計語義對齊模塊和健康狀態分類模塊構建網絡模型,將純化后的有標簽數據輸入到網絡模型中進行訓練,得到可用于診斷的網絡模型。
2.根據權利要求1所述的一種面向有限數據的半監督滾動軸承跨域故障診斷方法,其特征在于,所述強增強模塊包括隱變量提取模塊、生成對抗網絡gan和變分自編碼器vae;隱變量提取模塊、gan的生成器和判別器均由殘差卷積模塊組成,vae的編碼器和解碼器由若干深度卷積神經網絡模塊組成;隱變量提取模塊首個卷積層使用16×1的卷積核,用于提取短時特征,輔助模型自動學習故障相關特征,同時去除與故障無關的特征;其余卷積層均采用3×1的卷積核;每層卷積層之后均經過批量歸一化操作、激活操作和最大值池化操作;所述隱變量提取模塊的輸出,使用flatten操作,將提取的特征展開至一維特征表示作為隱變量xl,并作為生成器的輸入;gan的生成器將提取到的隱變量經過若干殘差卷積操作后產生一個與源域數據尺寸相同的樣本,記作gan的判別器將原始樣本x和作為輸入,對兩者進行區分,輸出當前輸入的樣本是否為真實樣本;所述gan的判別器輸入層采用大卷積核,后續若干層采用3×1的卷積核;變分自編碼器vae針對生成數據進行隱變量提取,并將提取到的隱變量與針對原始數據提取到的隱變量xl計算其差異,并最小化該差異,以降低數據生成過程中信息丟失情況。
3.根據權利要求1所述的一種面向有限數據的半監督滾動軸承跨域故障診斷方法,其特征在于,所述決策邊界自適應模塊采用基于k-means的聚類方法學習樣本決策邊界;通過最大化樣本平均熵來優化決策邊界。
4.根據權利要求1所述的一種面向有限數據的半監督滾動軸承跨域故障診斷方法,其特征在于,所述源域無標簽數據確定其偽標簽,具體為,將樣本映射至高維空間,并根據最優決策邊界計算樣本與聚簇中心之間的歐式距離,將距離最小的聚簇中心對應的類別標簽賦給樣本得到樣本的偽標簽
5.根據權利要求1所述的一種面向有限數據的半監督滾動軸承跨域故障診斷方法,其特征在于,所述弱增強模塊,涉及三種增強方式:
6.根據權利要求1所述的一種面向有限數據的半監督滾動軸承跨域故障診斷方法,其特征在于,所述語義對齊模塊輸入為源域有標簽數據強增強數據和經偽標簽篩選后的純化數據經過卷積網絡映射至高維空間后,學習跨域不變特征,得到高維特征z,并將z輸入至健康狀態分類模塊,得到模型的預測輸出結果。
7.根據權利要求1所述的一種面向有限數據的半監督滾動軸承跨域故障診斷方法,其特征在于,所述原始數據中有一個域有標簽,其余若干域無標簽。
技術總結
本發明屬于故障診斷技術領域,公開一種面向有限數據的半監督滾動軸承跨域故障診斷方法。源域有標簽數據經強增強模塊生成強增強數據;強增強數據和源域有標簽數據經決策邊界自適應模塊獲得決策邊界;根據決策邊界為源域無標簽數據確定其偽標簽;源域有標簽數據進行弱增強,根據弱增強數據計算初始置信度,并生成置信度閾值;置信度閾值對源域無標簽數據的偽標簽進行標簽篩選,得到純化數據;純化數據輸入語義對齊模塊和健康狀態分類模塊到網絡模型中進行訓練,得到可用于診斷的模型。本發明所提出的方法既解決跨域潛在的巨大分布差異問題,同時也可以解決源域數據只有少量數據有標簽的問題,可以進一步促進跨域故障診斷模型在實際生產中的應用。
技術研發人員:畢遠國,王藝蒙,付饒,郭威,劉炯驛
受保護的技術使用者:東北大學
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!