基于三維高斯和觸感圖像融合的智能機器人安全操作方法
本發明涉及智能機器人,具體涉及一種基于三維高斯和觸感圖像融合的智能機器人安全操作方法。
背景技術:
1、傳統的機器人工作模式單一、操縱靈活性差、缺乏理解能力,無法適應非計劃性、隨機性應用場景,難以滿足廣泛應用和具身智能化的要求。
2、相關技術中,隨著大規模預訓練模型的迅速發展,基于大模型的具身智能在各類任務中取得了顯著成果,展現了強大的泛化能力和廣闊的應用前景。具身智能系統通過感知、理解和與物理世界互動,能夠執行復雜任務,成為人工智能領域的重要方向。
3、例如,在論文(li?p,?wu?h,?huang?y,?et?al.?gr-mg:?leveraging?partiallyannotated?data?via?multi-modal?goal?conditioned?policy[j].?arxiv?preprintarxiv:2408.14368,?2024.)提出了gr-mg方法,結合語言指令和目標圖像,實現通用的機器人操作。在訓練階段,gr-mg利用帶有文本和圖像的軌跡數據進行條件訓練,并在缺少文本時僅依賴圖像。推理階段,gr-mg通過擴散式圖像編輯模型根據語言指令生成目標圖像,再結合文本和生成的圖像執行任務。為了提高目標圖像的準確性,設計了進度引導的圖像生成模型,顯著提升了圖像保真度和任務執行性能。該方法有效利用大量部分標注的數據,增強了機器人在不同環境中的泛化能力。
4、然而,傳統的多模態大模型控制方案主要依賴第三視角和手部視角來提取rgb特征,單一的視覺信息導致夾持器控制穩定性不足,從而影響任務執行的穩定性和效率。
技術實現思路
1、(一)解決的技術問題
2、針對現有技術的不足,本發明提供了一種基于三維高斯和觸感圖像融合的智能機器人安全操作方法,解決了單一的視覺信息導致夾持器控制穩定性不足的技術問題。
3、(二)技術方案
4、為實現以上目的,本發明通過以下技術方案予以實現:
5、一種基于三維高斯和觸感圖像融合的智能機器人安全操作方法,所述智能機器人的機械臂的末端安裝有夾持器;包括:
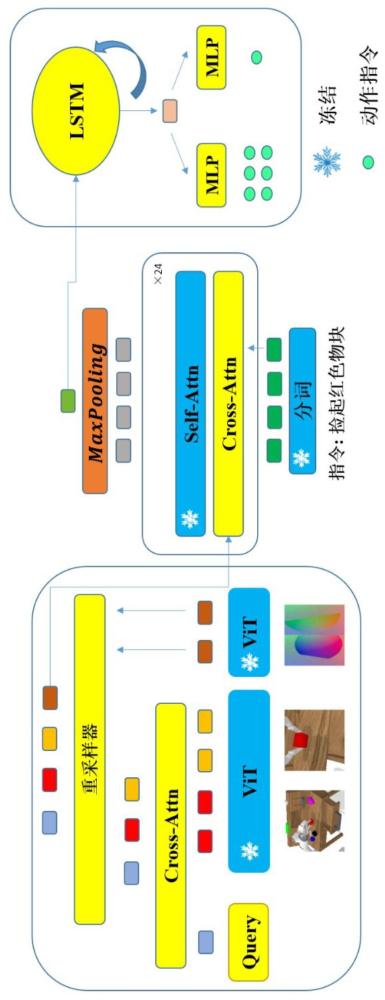
6、收集機械臂手部視角和第三視角的rgb圖像序列,并通過預訓練的vit模型提取所述rgb圖像序列的圖像特征;
7、基于預先保存的查詢向量以及交叉注意力的權重參數,對所述圖像特征進行交叉注意力計算,以獲取基于三維高斯的高維特征;
8、通過力傳感器實時感應所述夾持器的左右兩個夾爪與被操作對象的接觸力分布,獲取二維的rgb觸感圖像序列,并通過所述vit模型提取所述rgb觸感圖像序列的觸感圖像特征;
9、將所述高維特征與所述觸感圖像特征分別作為重采樣器的輸入,獲取相應的特征序列后進行拼接;
10、將拼接結果與語言指令作為特征融合解碼器的輸入,并采用lstm策略頭對所述特征融合解碼器的輸出進行動作預測,以獲取所述夾持器的位姿變化量以及所述夾持器的下一狀態;
11、基于所述夾持器的當前位姿與所述位姿變化量,計算目標位姿,以確定所述夾持器的移動方向和距離。
12、優選的,在所述計算目標位姿的過程中,引入基于安全區域的動態反饋優化控制算法,包括:
13、(1)設計位姿控制器:
14、基于所述位姿變化量,定義目標位置與當前位置之間的第一位置誤差:
15、
16、其中,e1為第一位置誤差;為位姿變化量;為待計算的夾持器在目標位置的目標位姿;為夾持器在當前位置的當前位姿;
17、采用位姿控制器來計算控制輸入,確保夾持器平滑地朝著目標位置移動:
18、
19、其中,u1為選用pd控制器的位姿控制器的輸出;kp1、kd1分別為第一比例和第一微分增益;為第一位置誤差的變化率;
20、(2)設計安全區域控制器:
21、將所述安全區域設定為一個高度為h的平面區域,在該區域外整個所述機械臂的自由活動不受限制,在該區域內一旦所述夾持器接近區域邊界,所述安全區域控制器輸出一個遠離所述區域邊界的控制量:
22、
23、其中,u2為安全區域控制器的輸出;kp2、kd2分別為第二比例和第二微分增益;e2為當前位置與安全區域的第二位置誤差,e2在z方向上的分量,dz為夾持器的末端到區域邊界的距離;為第二位置誤差的變化率;
24、(3)指定控制目標的評價函數:
25、基于目標位姿與當前位姿的差值平方,設計所述位姿控制器的第一評價函數:
26、
27、其中,t0為初始時間點;t為預設的時間跨度;‖?‖為向量的模;t為時間變量;
28、基于夾持器的末端到區域邊界的距離與安全區域高度的差值平方,設計所述安全區域控制器的第二評價函數:
29、
30、(4)計算預測評價梯度下降值,并構建狀態反饋機制:
31、設計飽和抑制函數:
32、
33、其中,為評價梯度,i取1或2;α為梯度幅值上限;
34、采用梯度下降法獲取單目標優化后的輸入:
35、
36、其中,ui為基礎控制輸入;λ為學習率;kα為與飽和抑制函數相對應的增益系數;
37、構建所述狀態反饋機制以使機器人狀態快速收斂,加入狀態反饋后的單目標控制器表示為:
38、
39、其中,kfb為狀態反饋增益矩陣,下標fb表示狀態反饋,為目標狀態,xi為當前實際狀態;
40、綜合輸出為:
41、
42、(5)計算新的安全目標位姿,以確保所述夾持器避免觸碰所述區域邊界:
43、
44、其中,為更新后的目標位姿。
45、優選的,所述查詢向量以及交叉注意力的權重參數的獲取過程包括:
46、在機械臂操作場景內選定一個固定的世界坐標系;
47、采用p個三維高斯分布表示所述機械臂操作場景,每個三維高斯由一個d維向量表示,形式為,其中d=10+|csem+2|,且m、s、r、c分別為均值、尺度、旋轉向量和語義種類,為實數集,csem為語義標簽的數量;
48、初始化和可學習向量;其中d為可學習向量的維度,且d>>d,用于表示高斯的參數屬性,qjg為一個可學習的三維空間特征,上標g表示與高斯表示相關的查詢向量,下標j表示高斯核的索引;
49、根據初始化后的高斯核進行體素化處理,每一體素網格的占用預測結果通過下式計算:
50、
51、其中,為各個高斯分布對所選定的世界坐標系內任意位置p的貢獻之和,用于表征占用預測結果;為三維高斯占用預測分布在點p處的值;為點p的鄰近高斯集合;exp為指數函數;σ為協方差矩陣;s=diag(s)表示尺度矩陣,diag為提取對角線元素的函數,r=q2r(q)是將用于表征三維空間旋轉的四元數q轉換為旋轉矩陣的函數;
52、若任一體素網格占用預測結果大于一定閾值thresholds,認為該體素網格被占據,即任一體素網格位置v表示為:
53、
54、將占用的體素網格位置集合表示為:
55、
56、其中,|?|為集合的大小;m為用的體素網格位置數量;
57、將被占據的體素網格位置對應的特征表示為稀疏張量:
58、
59、其中,f(v)為任一體素網格位置v的稀疏張量;fs為與集合s相對應的稀疏張量集合;
60、p個高斯核分別對應p個特定的體素網格位置{v1,v2,…,vp}∈s,定義保留的體素集合ps為:
61、
62、對ps中的每個體素網格位置vj應用稀疏卷積核,得到輸出特征f'(v):
63、
64、其中,為卷積核的相對位置集合;wk為對應于相對位置k的卷積權重;為相對位置偏移;σ為非線性激活函數relu;
65、在機械臂操作場景中采集n個視角的rgb圖像,對于每個視角的rgb圖像,通過vit模型編碼得到相應的圖像特征:
66、
67、其中,為第?n個視角的圖像特征;in為第n個視角的rgb圖像;
68、將初始化的查詢向量queryg與進行交叉注意力機制運算,得到:
69、
70、其中,cross_attn為交叉注意力;
71、將查詢向量queryg通過一組多層感知器mlp進行處理,得到更新后的高斯核參數:
72、
73、其中,分別為更新后的均值、尺度、旋轉向量和語義種類;
74、將更新后的高斯核直接替換原有高斯核,新的高斯核參數表示為:
75、
76、將嵌入大小為x×y×z的目標體素網格中;
77、對于每個新的三維高斯,根據其尺度屬性計算其鄰域的半徑,并重新計算每個體素網格的占用預測結果;
78、對于重新確定的每個被占用的體素網格,計算其語義種類對應標簽clabel與預測值之間的交叉熵損失ce:
79、
80、其中,為損失函數;表示被占用的體素網格集合;下標label表示標簽;
81、通過所述損失函數更新模型參數,訓練完成后保存其中的查詢向量queryg以及交叉注意力cross-attn的權重參數。
82、優選的,所述rgb圖像序列的圖像特征表示為:
83、
84、其中,為t時刻的圖像特征,上標表示視覺;分別為t時刻機械臂手部視角和第三視角的rgb圖像;⊕為逐元素相加符號;
85、所述基于預先保存的查詢向量以及交叉注意力的權重參數,對所述圖像特征進行交叉注意力計算,以獲取基于三維高斯的高維特征;表示為:
86、
87、其中,為t時刻的基于三維高斯的高維特征。
88、優選的,所述通過所述vit模型提取所述rgb觸感圖像序列的觸感圖像特征;表示為:
89、
90、其中,為t時刻的觸感圖像特征;分別為t時刻夾持器的左右兩個夾爪的rgb觸感圖像,上標lta、rta分別表示左、右觸覺感知。
91、優選的,所述將所述高維特征與所述觸感圖像特征分別作為重采樣器的輸入,獲取相應的特征序列后進行拼接;包括:
92、將所述高維特征與所述觸感圖像特征分別輸入重采樣器的k、v全連接層,并采用一組可學習向量q輸入重采樣器的q全連接層:
93、
94、其中,qr∈為對應于重采樣器的可學習參數的查詢向量,為重采樣器查詢向量的數量,為隱藏維度的大小,分別為鍵和值的線性變換矩陣,dg/ta表示高維特征或觸感圖像特征的維度大小;分別為高維特征輸入生成的轉換后的鍵和值向量;分別為觸感圖像特征輸入生成的轉換后的鍵和值向量;分別為由重采樣器輸出的與高維特征、觸感圖像特征對應的特征序列;softmax為激活函數;上標t為轉置符號;
95、將得到的兩個特征序列進行拼接:
96、
97、其中,為t時刻的拼接結果,上標g-ta表示高斯特征和觸覺特征的融合;concat為拼接操作。
98、優選的,所述將拼接結果與語言指令作為特征融合解碼器的輸入,并采用lstm策略頭對所述特征融合解碼器的輸出進行動作預測,以獲取所述夾持器的位姿變化量以及所述夾持器的下一狀態;包括:
99、通過所述特征融合解碼器執行特征融合過程,并與所述語言指令進行整合,輸出;其中特征融合過程表示為:
100、
101、其中,為t時刻第l個交叉注意層的輸出;tanh為雙曲正切函數;α∈為一個可學習的參數,用于控制融合過程中不同特征的貢獻;a為交叉或自注意力運算;分別為交叉注意層的可學習參數;分別為t時刻第l、l+1個自注意層的輸出;分別為自注意層的可學習參數;l為交替循環的自注意層和交叉注意層的數量之和,且為偶數;nl為語言指令的數量;
102、采用所述lstm策略頭對輸出xt進行動作預測,以獲取所述夾持器的位姿變化量以及所述夾持器的下一狀態;表示為:
103、
104、其中,maxpooling為最大池化層,為其輸出;ht、ht-1分別為t、t-1時刻的隱藏狀態;分別為預測的所述夾持器的位姿變化量以及所述夾持器的下一狀態,且狀態是指夾持器的左右兩個夾爪處于張開或閉合狀態。
105、一種基于三維高斯和觸感圖像融合的智能機器人安全操作系統,所述智能機器人的機械臂的末端安裝有夾持器;包括:
106、收集模塊,用于收集機械臂手部視角和第三視角的rgb圖像序列,并通過預訓練的vit模型提取所述rgb圖像序列的圖像特征;
107、計算模塊,用于基于預先保存的查詢向量以及交叉注意力的權重參數,對所述圖像特征進行交叉注意力計算,以獲取基于三維高斯的高維特征;
108、提取模塊,用于通過力傳感器實時感應所述夾持器的左右兩個夾爪與被操作對象的接觸力分布,獲取二維的rgb觸感圖像序列,并通過所述vit模型提取所述rgb觸感圖像序列的觸感圖像特征;
109、采樣模塊,用于將所述高維特征與所述觸感圖像特征分別作為重采樣器的輸入,獲取相應的特征序列后進行拼接;
110、預測模塊,用于將拼接結果與語言指令作為特征融合解碼器的輸入,并采用lstm策略頭對所述特征融合解碼器的輸出進行動作預測,以獲取所述夾持器的位姿變化量以及所述夾持器的下一狀態;
111、確定模塊,用于基于所述夾持器的當前位姿與所述位姿變化量,計算目標位姿,以確定所述夾持器的移動方向和距離。
112、一種存儲介質,其存儲有用于基于三維高斯和觸感圖像融合的智能機器人安全操作的計算機程序,其中,所述計算機程序使得計算機執行如上所述的智能機器人安全操作方法。
113、一種電子設備,包括:
114、一個或多個處理器;存儲器;以及一個或多個程序,其中所述一個或多個程序被存儲在所述存儲器中,并且被配置成由所述一個或多個處理器執行,所述程序包括用于執行如上所述的智能機器人安全操作方法。
115、(三)有益效果
116、本發明提供了一種基于三維高斯和觸感圖像融合的智能機器人安全操作方法。與現有技術相比,具備以下有益效果:
117、本發明中,首先收集機械臂手部視角和第三視角的rgb圖像序列,以獲取基于三維高斯的高維特征;接著通過力傳感器實時感應夾持器的末端與被操作對象的接觸力分布,獲取二維的rgb觸感圖像序列,以獲取觸感圖像特征;然后將高維特征與觸感圖像特征分別作為重采樣器的輸入,獲取相應的特征序列后進行拼接,將拼接結果與語言指令作為特征融合解碼器的輸入,并采用lstm策略頭對特征融合解碼器的輸出進行動作預測;最終基于夾持器的當前位姿與位姿變化量,計算用于確定夾持器的移動方向和距離的目標位姿。通過結合視覺信息與力傳感器數據,實時調整夾持器的抓取策略,優化操作過程,提高了機械臂在復雜任務中的可靠性和效率。
- 還沒有人留言評論。精彩留言會獲得點贊!