深度強化學習模型的更新方法及裝置與流程
本發明屬于深度強化學習模型技術類領域,具體涉及到深度強化學習模型的更新方法及裝置。
背景技術:
1、深度強化學習(deep?reinforcement?learning,?drl)是機器學習的一個分支,結合了深度學習的感知能力和強化學習的決策能力,用于解決復雜環境中的序列決策問題
2、現有深度強化學習模型的更新方法存在以下問題:同步更新效率低:傳統方法采用同步更新策略(如a3c的同步多線程),在異構計算資源下易出現等待延遲,導致資源利用率低。經驗回放機制不足:固定優先級或均勻采樣的經驗回放(experience?replay)難以平衡探索與利用,影響收斂速度。模型穩定性差:動態環境中,直接更新策略網絡可能導致策略突變,引發系統震蕩。資源消耗大:頻繁的全局模型更新對計算和存儲資源需求高,難以在邊緣設備部署。
技術實現思路
1、本發明所要解決的技術問題在于克服上述現有技術的缺點,提供深度強化學習模型的更新方法及裝置。
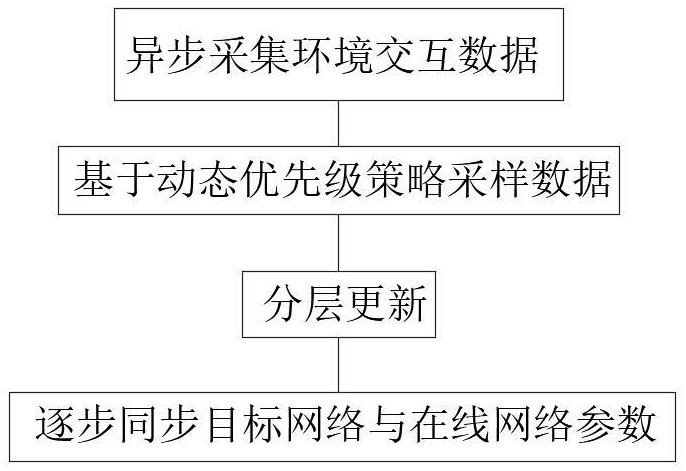
2、解決上述技術問題所采用的技術方案是:深度強化學習模型的更新方法,包括下述具體步驟:
3、步驟一:通過多個并行執行單元異步采集環境交互數據;
4、步驟二:基于動態優先級策略從經驗池中采樣數據,所述優先級由td-error和策略相似度聯合確定;
5、步驟三:采用分層更新策略,對網絡的關鍵層與非關鍵層設置不同更新頻率;
6、步驟四:通過軟更新技術逐步同步目標網絡與在線網絡參數。
7、通過上述技術方案,提升同步更新效率,加速收斂,提高模型穩定性,降低資源消耗。
8、進一步的,所述動態優先級策略中采樣優先級由兩部分組成:時序差分誤差和策差異度量,公式為:其中,是經驗數據的時序差分誤差(td-error),衡量當前價值估計的偏差,具體表達式為:是環境反饋的即時獎勵,折扣因子,控制未來獎勵的重要性,是目標網絡對下移狀態和動作的價值估計,在線網絡對當前狀態和動作的價值估計,新舊策略之間的kl散度,量化策略更新的幅度,防止策略突變,是更新前的策略網絡輸出的動作概率分布,是更新后的策略網絡輸出的工作概率分布,是平衡系數,控制td-error與策略差異的權重。
9、通過上述技術方案,解決高td-error樣本表示當前模型預測不準確,需優先學習的問題,而通過高kl散度樣本表示策略變化來判斷是否過度偏離歷史經驗。
10、進一步的,分層更新頻率控制采用下述公式:
11、將深度網絡劃分為關鍵層和非關鍵層,定義更新頻率:
12、其中,是基礎更新頻率,,是調整系數。
13、通過上述技術方案,通過異步更新機制減少等待時間,提高資源利用率。
14、進一步的,異步梯度更新采用下述公式:其中,是學習率,是損失函數。
15、通過上述技術方案,降低更新消耗。
16、進一步的,計算更新前后策略的kl散度,確保不超過安全閾值;若,則進行更新,若,拒絕本次更新并回滾至舊策略。
17、通過上述技術方案,提高模型穩定性。
18、進一步的,包括數據采集模塊、經驗池管理模塊、異步更新模塊和安全性校驗模塊,數據采集模塊負責為通過多源傳感器獲取環境狀態,經驗池管理模塊負責為存儲并動態加權采樣經驗數據,異步更新引擎負責為分塊更新神經網絡參數,安全性校驗模塊負責為通過對抗樣本測試驗證模型穩定性。
19、本發明的有益效果如下:本發明通過異步更新機制減少等待時間,提高資源利用率,使效率提升,通過動態優先級采樣使訓練速度提升,加速收斂,分塊更新策略降低計算開銷,節省資源,通過對抗測試的模型錯誤率降低,提高安全性。
技術特征:
1.深度強化學習模型的更新方法,其特征在于,包括下述具體步驟:
2.根據權利要求1所述的深度強化學習模型的更新方法,其特征在于,所述動態優先級策略中采樣優先級由兩部分組成:時序差分誤差和策差異度量,公式為:其中,是經驗數據的時序差分誤差(td-error),衡量當前價值估計的偏差,具體表達式為:是環境反饋的即時獎勵,折扣因子,控制未來獎勵的重要性,是目標網絡對下移狀態和動作的價值估計,在線網絡對當前狀態和動作的價值估計,新舊策略之間的kl散度,量化策略更新的幅度,防止策略突變,是更新前的策略網絡輸出的動作概率分布,是更新后的策略網絡輸出的工作概率分布,是平衡系數,控制td-error與策略差異的權重。
3.根據權利要求2所述的深度強化學習模型的更新方法,其特征在于,分層更新頻率控制采用下述公式:
4.根據權利要求3所述的深度強化學習模型的更新方法,其特征在于,異步梯度更新采用下述公式:其中,是學習率,是損失函數。
5.根據權利要求4所述的深度強化學習模型的更新方法,其特征在于,計算更新前后策略的kl散度,確保不超過安全閾值,若,則進行更新,若,拒絕本次更新并回滾至舊策略。
6.一種用于如權利要求5所述的深度強化學習模型的更新方法的裝置,其特征在于,包括數據采集模塊、經驗池管理模塊、異步更新模塊和安全性校驗模塊,數據采集模塊負責為通過多源傳感器獲取環境狀態,經驗池管理模塊負責為存儲并動態加權采樣經驗數據,異步更新引擎負責為分塊更新神經網絡參數,安全性校驗模塊負責為通過對抗樣本測試驗證模型穩定性。
技術總結
本發明公開了深度強化學習模型的更新方法及裝置,屬于深度強化學習模型技術類領域,該深度強化學習模型的更新方法及裝置,包括下述具體步驟:步驟一:通過多個并行執行單元異步采集環境交互數據;步驟二:基于動態優先級策略從經驗池中采樣數據,所述優先級由TD?error和策略相似度聯合確定;步驟三:采用分層更新策略,對網絡的關鍵層與非關鍵層設置不同更新頻率;步驟四:通過軟更新技術逐步同步目標網絡與在線網絡參數。本發明通過異步更新機制減少等待時間,提高資源利用率,使效率提升,通過動態優先級采樣使訓練速度提升,加速收斂,分塊更新策略降低計算開銷,節省資源,通過對抗測試的模型錯誤率降低,提高安全性。
技術研發人員:張富
受保護的技術使用者:上海佳投互聯網技術集團有限公司
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!